Topic Overview
Monolith vs Microservices
When one app is enough—and when splitting into services actually helps. Plain comparison of monoliths and microservices, how teams feel the difference in production, and how to migrate without a big-bang rewrite.
Your team ships a new feature. In a monolith, one pull request touches the same repo everyone else uses, one test suite runs, and one deploy button updates the whole product. In microservices, the same feature might need changes in three repos, three pipelines, and a careful rollout order so the order service does not call a payment API that is not live yet.
Neither shape is “the winner.” A monolith is often the fastest way to learn what you are building. Microservices help when organizational and scaling pain—not a conference talk—forces you to split. This guide walks through what each architecture actually means, what users and teams experience when things go right or wrong, when to choose each, and how strong interview answers sound without pretending distributed systems are free.
Two ways to package the same product
Picture an online store. Customers browse products, place orders, and pay. You can build that product in two broad shapes.
In a monolith, users, catalog, orders, and payments live inside one running application. They share one codebase (or one tightly linked repo), usually one main database, and one deployment. When you fix a typo in checkout, you deploy the whole app.
In microservices, you split the product into separate services—for example User, Catalog, Order, and Payment—each with its own code, its own deploy pipeline, and often its own database. Services talk over the network (HTTP, gRPC, or messages on a queue). You can deploy Payment on Tuesday without redeploying Catalog.
The split is about boundaries and ownership, not about making every function its own service. A healthy microservice owns a clear piece of business logic and the data that goes with it.
Monolith: one unit, one deploy
A monolith is not “bad old code.” It is a deliberate choice: keep related logic together until the cost of staying together is higher than the cost of distribution.
What it looks like in practice
All modules run in the same process (or a small number of processes behind one load balancer). When Order needs User details, it calls a function in the same app—no network hop. When Order and Payment both update state, they can often use one database transaction: either the order is created and paid, or neither happens.
That local call path matters for speed and for correctness. There is no “payment service timed out but order service already committed” drama inside a single transaction boundary—though you still have to design error handling well.
Where monoliths shine
| Strength | In plain words | Why teams like it early |
|---|---|---|
| Fast to build | One repo, one mental model | You learn the domain before drawing service lines |
| Simple operations | One deploy artifact, one log stream | Fewer moving parts at 2 a.m. |
| In-process calls | Modules talk without HTTP | Lower latency; easier local debugging |
| Strong consistency | One database, ACID transactions | Checkout and inventory stay in sync more easily |
Where monoliths hurt
| Pain | What happens | What users or teams feel |
|---|---|---|
| Scale everything together | Traffic spikes on search force you to scale checkout too | Higher cloud bill; slow unrelated pages |
| Deploy risk | One bad change can break login and payments | Full-site outage from a small mistake |
| Team friction | Many teams edit the same codebase | Merge conflicts, slow releases, “who owns this file?” |
| Technology lock-in | Whole app shares one stack | Hard to try a new language for one hot path |
Monolith pain often shows up as coordination pain before it shows up as traffic pain. If ten engineers step on each other’s releases, splitting services is sometimes an org fix as much as a performance fix.
Microservices: many small owners
Microservices means independently deployable services with loose coupling over the network. Each service should own its data and expose a clear API. “Micro” describes scope, not line count—a service can be thousands of lines if the boundary is right.
What it looks like in practice
Order Service receives “create order.” It calls User Service to verify the account, writes to its order database, then calls Payment Service. Each hop adds latency and failure modes: Payment can be slow, return an error, or be down while Order is still up.
Teams accept that tradeoff when independent scaling, independent releases, or team boundaries matter more than the simplicity of one process.
Where microservices shine
| Strength | In plain words | Good when |
|---|---|---|
| Independent scale | Scale only the hot service | Search gets 10× traffic; billing does not |
| Independent deploy | Ship Payment without touching Catalog | Teams release on their own schedule |
| Fault isolation (partial) | Bug in recommendations does not crash checkout | Boundaries and timeouts are designed well |
| Technology fit | Pick the right tool per service | One team needs a specialized search engine |
Where microservices hurt
| Pain | What happens | What users or teams feel |
|---|---|---|
| Network everywhere | Every cross-service step can fail or slow down | Checkout spins; mysterious timeouts |
| Distributed data | No single transaction across services | Paid but order missing—or duplicate charges without careful design |
| Operational load | More repos, more dashboards, more on-call rotations | Incidents span five services |
| Testing complexity | End-to-end tests need many services running | Slower CI; gaps in staging |
Microservices do not automatically isolate failure. If Order must call Payment synchronously and Payment is down, checkout still fails—the failure is just on the network instead of inside one process.
The diagram below contrasts the two shapes at a glance: one box and one database versus several services with their own data stores.
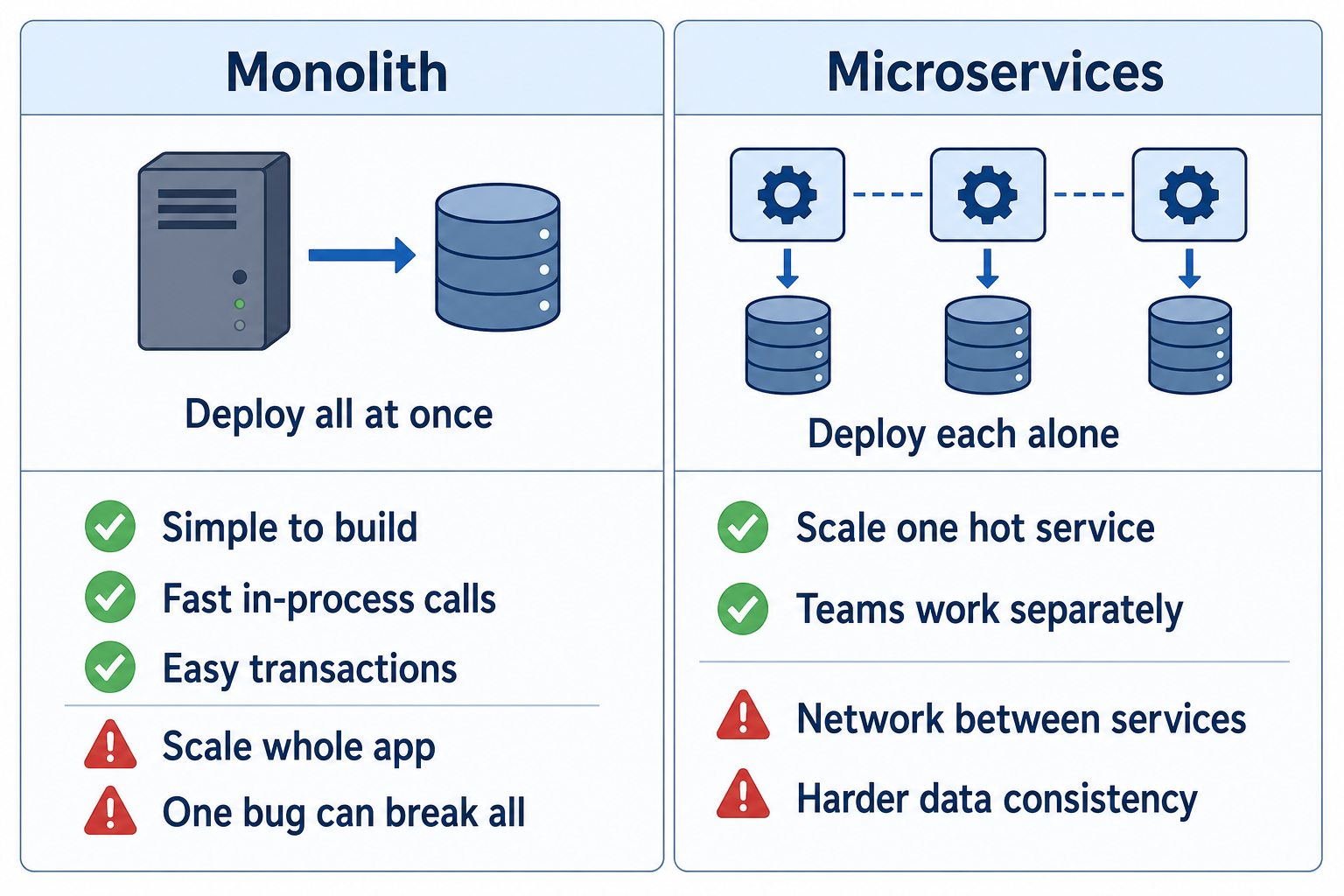
Figure: A monolith keeps modules and data together; microservices split deploy units and databases.
Side-by-side: the decision table interviewers expect
These rows are worth memorizing as tradeoffs, not as slogans. Strong answers always tie a row to a scene (team size, traffic shape, consistency need).
| Topic | Monolith | Microservices |
|---|---|---|
| Code layout | One codebase (or one main app) | Many codebases / services |
| Deployment | Deploy the whole app | Deploy services separately |
| Data | Often one shared database | Database (or schema) per service |
| Communication | In-process function calls | Network: HTTP, gRPC, messages |
| Consistency | Easier ACID in one DB | Eventual consistency, sagas, compensations |
| Scaling | Scale copies of the entire app | Scale individual hot services |
| Complexity | Lower until the app grows huge | Higher from day one of the split |
| Best early signal | “We need speed and clarity” | “Teams or traffic force boundaries” |
If you only remember one row: monoliths optimize for development simplicity; microservices optimize for independent change at the cost of distributed operations.
When to choose a monolith
Default to a monolith when the problem and the team are still forming. Most products do not know their service boundaries on day one. A monolith lets you rename tables, move modules, and ship features without negotiating cross-service versioning.
Choose (or stay on) a monolith when several of these are true:
- Small team — roughly one pizza team can own the whole product without constant merge pain.
- Unclear domain — you are still discovering what “order” vs “shipment” means in your business.
- Strong consistency on the happy path — checkout, inventory, and payment must commit together often.
- Moderate traffic — you can scale copies of the whole app behind a load balancer and that is enough for now.
- Speed over autonomy — you need one deploy a day, not five teams releasing independently.
Staying monolithic is not “avoiding scale forever.” It is delaying distribution until you have evidence—slow deploys, team gridlock, or one module needing 10× the CPU of everything else.
When to consider microservices
Consider splitting when pain comes from boundaries, not from boredom with a monolith.
Signals that often justify services:
- Team boundaries — three teams block each other’s releases every week.
- Different scaling profiles — image processing needs GPUs; account settings need almost none.
- Different reliability targets — search can be stale; payments cannot.
- Regulatory or security isolation — card data must live in a smaller audited surface.
- Replaceable subsystems — you must swap the search engine without rewiring the whole app.
Microservices are a poor fit when the real problem is bad code inside one app. Splitting a tangled monolith into tangled services gives you distributed tangling—the hardest kind to debug.
Migration: start whole, split on purpose
The usual production story is not “monolith bad, microservices day one.” It is monolith first, extract when the boundary is obvious.
Strangler fig pattern
Named after a tree that grows around a host, the strangler fig pattern routes traffic gradually from the old monolith to new services:
- Build the new service beside the monolith (do not delete the old path yet).
- Route a slice of traffic—for example 5% of “create order” calls—to the new service behind a gateway or load balancer.
- Watch metrics and errors; increase the percentage when behavior matches.
- Move data carefully—often dual-write or sync jobs—then shift reads.
- Remove the old code path from the monolith only when the new service owns the domain.
You keep shipping during migration because the monolith still handles most traffic until each slice is proven.
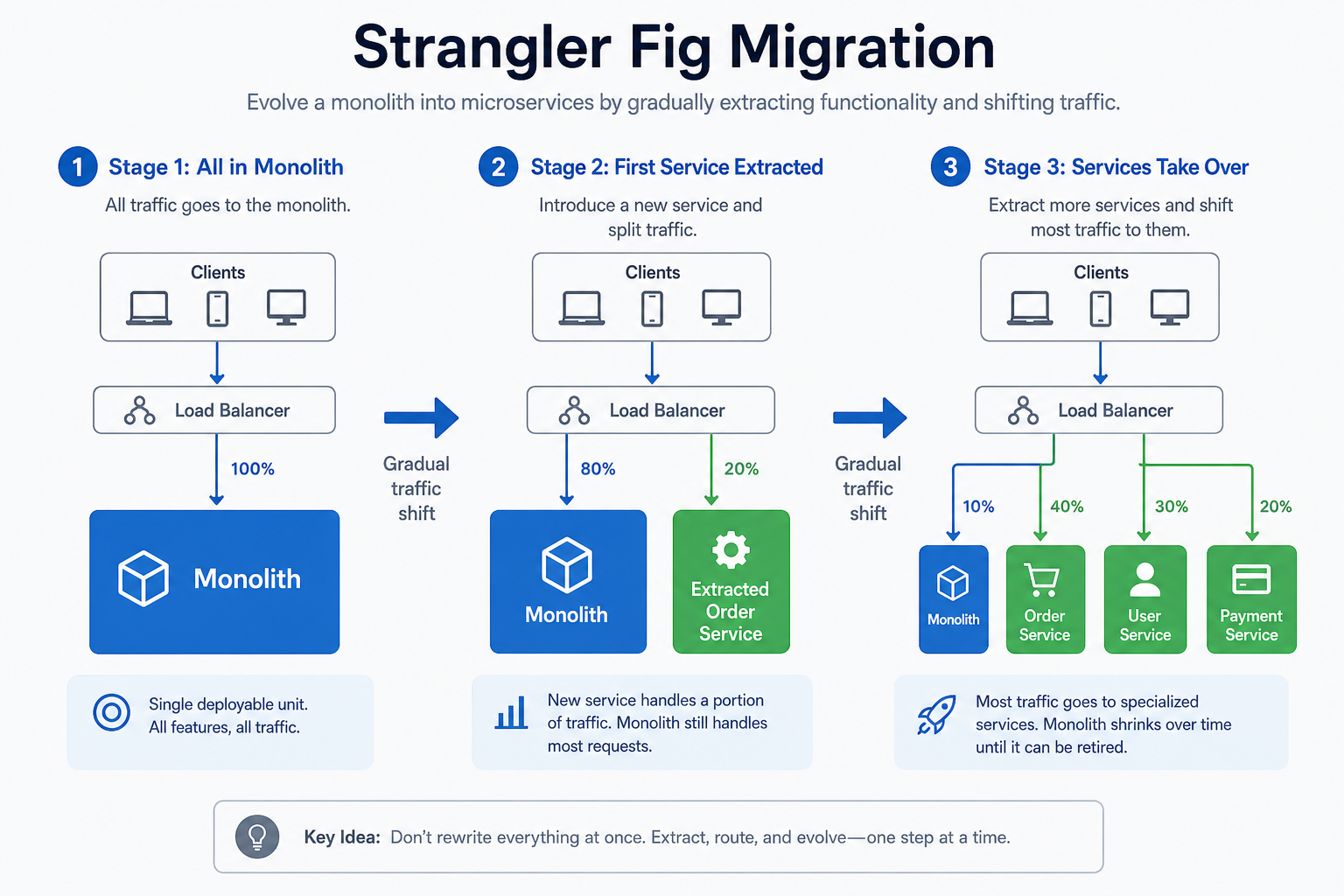
Figure: New services wrap the monolith; traffic shifts in steps instead of one risky cutover.
Data during extraction
The hardest part is rarely HTTP—it is who owns the rows. If Order Service gets its own database, you must decide how historical orders migrate, how long you dual-write to the monolith database, and how you detect mismatches. Plans often include:
- Dual write — application writes to monolith tables and new service tables for a period.
- Backfill job — copy old rows in batches with verification.
- Read switch — point reads to the new store only after counts and samples match.
- Rollback path — keep the monolith path feature-flagged until confidence is high.
Skipping these steps is how teams get split brain: two sources of truth for the same order id.
Common pitfalls (and what to do instead)
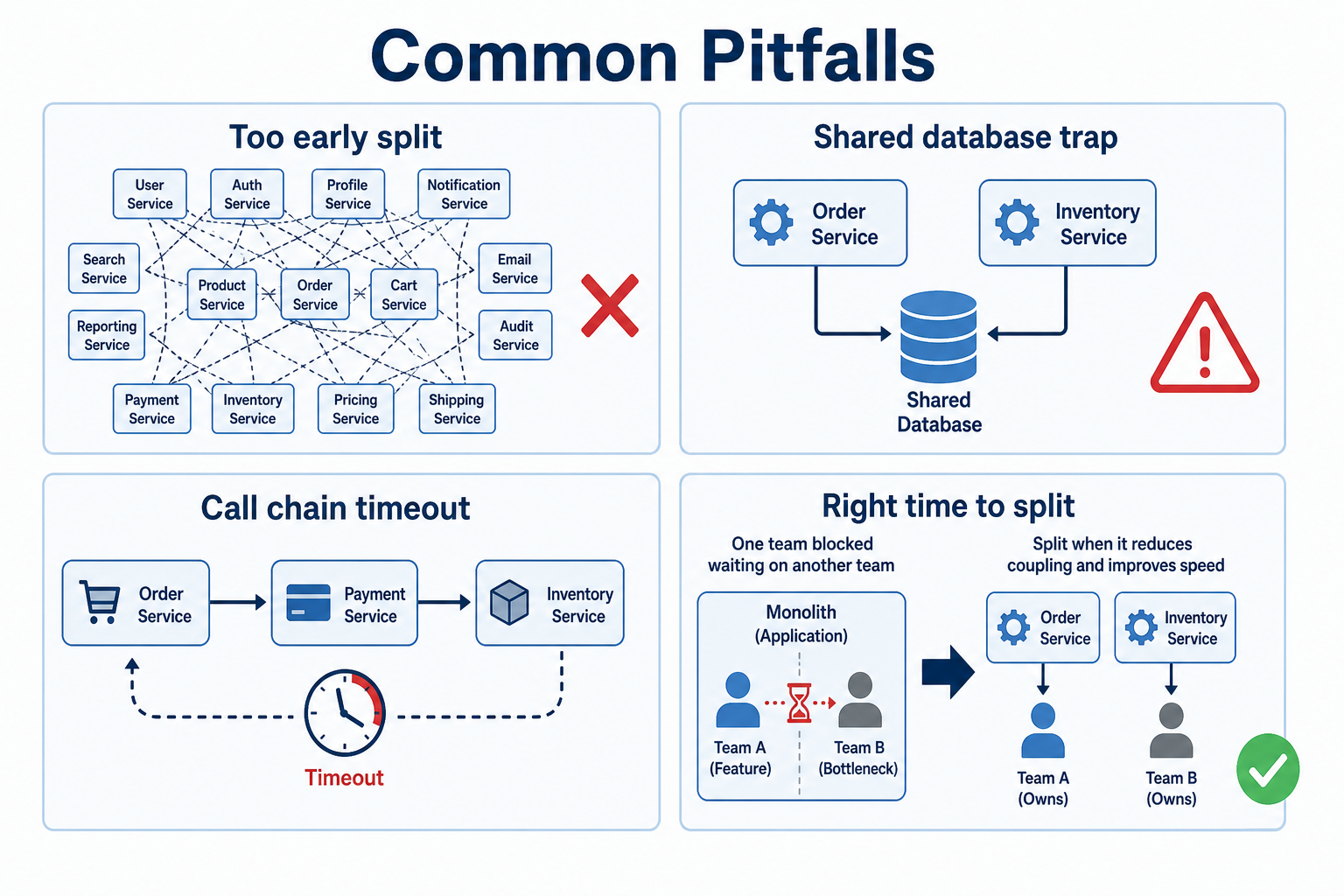
Figure: Split too early, share databases across “services,” or chain synchronous calls without timeouts.
| Pitfall | What goes wrong | Better direction |
|---|---|---|
| Microservices too early | Fifteen tiny services before product-market fit | Stay monolith until a concrete boundary hurts |
| Shared database | Two “services” fight over the same tables | Each service owns its schema; integrate via API or events |
| Sync call chains | Order → Inventory → Payment → Email serially | Timeouts, circuit breakers; async events where possible |
| Over-splitting | “UserService” and “UserProfileService” deploy separately | Fewer, thicker services aligned to team boundaries |
| No observability | “Payment failed” with no trace across hops | Correlation IDs, distributed tracing, per-service SLOs |
In interviews, naming one pitfall and its fix is often worth more than drawing twenty boxes.
A small scene: placing an order
Monolith path: A single createOrder handler validates the user from the local user module, inserts into the orders table, calls the payment module in-process, and commits. One failure surface for the developer; one deploy fixes a payment bug everywhere.
Microservices path: Order API validates the JWT, calls User Service, writes to Order DB, publishes OrderCreated or calls Payment Service. Payment failure must be handled explicitly—retry, compensate, or mark order failed. Operations need dashboards per service. Scale Order replicas without scaling User if Black Friday hits checkout hardest.
Same customer action; different operational contract. Neither path removes the need for good domain modeling.
Interview Questions
What is the difference?
Q: What is the difference between a monolithic architecture and microservices?
A: I would start with deployment and data boundaries. A monolith is one application you deploy as a unit. Modules inside it usually share a codebase and often one main database. Calls between modules are in-process, so they are fast and can participate in the same database transaction when designed that way.
Microservices split the product into separate deployable services, each with its own codebase and typically its own database. Services communicate over the network—HTTP, gRPC, or asynchronous messages. You can deploy or scale Order without redeploying Catalog, but you pay for latency, partial failures, and harder cross-service consistency.
The choice is not about which diagram looks more modern. It is about whether independent release and scale are worth distributed operations for this team and traffic today.
Weak answer to avoid: “Monolith is old; microservices are scalable.” (Scale can mean copies of a monolith too; microservices add complexity immediately.)
Tradeoffs and when to migrate
Q: What are the tradeoffs between monolith and microservices? When would you migrate?
A: Monoliths trade simplicity and strong local consistency for coupled scaling and coupled releases. That is ideal when the team is small, the domain is still moving, and one database transaction on checkout is a feature not a bug. The pain shows up when many teams share one repo, deploys become scary, or one corner of the app needs far more resources than the rest.
Microservices trade independent scale and team autonomy for network failures, operational overhead, and distributed data. I would migrate when I have evidence, not hype: repeated release gridlock between teams, a module with a clearly different scaling curve, or compliance that requires isolating payment data. I would not migrate because the codebase feels large—size alone is fixed by modular monolith patterns first.
Migration should be incremental: strangler fig routing, dual writes, measured traffic shifts, and rollback flags—not a weekend big bang.
Weak answer to avoid: “Migrate when you need to scale.” (Often you scale a monolith horizontally first; migrate when boundaries and org pain justify it.)
How would you split an e-commerce monolith?
Q: How would you identify service boundaries when splitting an e-commerce monolith?
A: I would look at business capabilities and who changes together, not at technical layers. User identity, catalog browsing, cart/checkout, payment, and fulfillment often have different change rates and different scaling needs. I would map bounded contexts: language that means one thing inside Order (an “order line”) might mean something else in Shipping.
I would extract one boundary at a time, starting where pain is highest—maybe Payment for compliance or Search for scale. Each service gets its own data; other teams call an API or consume events instead of reading foreign tables. I would keep the monolith running behind a gateway, route a percentage of traffic to the new service, and only delete monolith code after metrics and data checks match.
For checkout consistency across services, I would explain sagas or outbox patterns at a high level: if payment fails after order is created, there must be a defined compensation path—not silent duplicate charges.
Weak answer to avoid: “Split by controller or by database table count.” (Layers and table counts rarely match team or business boundaries.)
Failure and consistency
Q: Payment is down in a microservices checkout flow. What happens?
A: I would clarify whether Order calls Payment synchronously or starts payment via an async event. Sync: the user likely sees checkout fail or hang unless Order has timeouts and a clear error—“payment unavailable, try again.” Without timeouts, threads pile up and Order itself becomes unhealthy.
Async: Order might be created in PENDING_PAYMENT state; the user sees “processing.” Payment Service catches up later or a worker retries with idempotency keys so the same card is not charged twice. Support and finance need a visible state machine, not hidden partial success.
In a monolith, the same failure might surface as one exception in one process—but the user still cannot pay. The difference is where you observe and fix it: one log versus tracing across services. Microservices do not remove business failure; they require explicit cross-service policies.
Weak answer to avoid: “Microservices isolate failure so checkout still works.” (Only if checkout does not depend on payment.)
Modular monolith as middle ground
Q: Is there an option between monolith and microservices?
A: Yes—a modular monolith. You keep one deployable application but enforce module boundaries in code: Order does not reach into Payment’s tables; communication goes through well-defined interfaces inside the same process. Teams can own folders or packages with clear APIs even before any network split.
That gives many benefits of clear boundaries—easier testing of modules, clearer ownership—without running five CI pipelines on day one. If later one module needs independent scale, you extract the module that already has a clean seam instead of carving along random lines.
I would mention this in interviews to show I am not binary about architecture labels.
Weak answer to avoid: “You must pick monolith or microservices only.”
Strong answers on this topic share a pattern: name the user or team pain, pick a boundary, admit operational cost, and describe incremental migration instead of a rewrite fantasy.
FAQs
Q: Does “monolith” always mean one server?
A: No. A monolith is one application artifact, not one machine. You can run ten copies of the same monolith behind a load balancer and still call it a monolith. Each copy runs the full app—users, orders, payments together. What makes it monolithic is that you scale and deploy the whole unit, not individual features inside it.
People sometimes confuse monolith with “cannot scale.” Production monoliths scale horizontally until either traffic or team coordination becomes the bottleneck. Only then does splitting specific services start to pay off.
Q: How is microservices different from “we have a lot of microservices in name only”?
A: Real microservices have independent deployability and data ownership. If three services share one database and deploy together every time because schema changes must lock step, you have a distributed monolith—the worst of both worlds: network calls without autonomy.
Healthy microservices expose versioned APIs, own their schema, and can be rolled back independently when possible. Integration happens through those APIs or events, not through sneaky cross-database joins.
Q: Why do interviewers ask about monolith vs microservices if everyone uses microservices now?
A: Because most successful products started monolithic and many stay modular monoliths longer than Twitter talks suggest. Interviewers want to hear judgment: you can explain when distribution helps, when it hurts, and how you would migrate safely. Buzzwords without tradeoffs sound like resume-driven design.
They also want you to connect architecture to consistency, failure, and team structure—not just to box counts on a whiteboard.
Q: What is the strangler fig pattern in one sentence?
A: You build new services around the old monolith and gradually move traffic and data to them until the monolith stops handling that path—like growing a new tree around an old trunk instead of chopping the trunk on day one.
Q: Can microservices share a database temporarily during migration?
A: During a short, planned migration, teams sometimes dual-write or read from legacy tables while backfilling a service database. That is a transition tactic, not an end state. Leaving shared tables permanent creates hidden coupling: one team’s migration breaks another’s query. The goal is clear ownership with APIs or events at the boundary.
Q: How do I know if we split too early?
A: Warning signs include spending more time on plumbing (service discovery, cross-service auth, distributed debugging) than on features; incidents where no one knows which service owns a bug; and services so small that every user action crosses five network hops. If the org still fits one cohesive team and deploys comfortably, a modular monolith is usually cheaper than premature distribution.