Mock Interviewer
Ask Coach
Tap a question to start, or type your own below.
Distributed Search System Design
Visual Problem Diagram
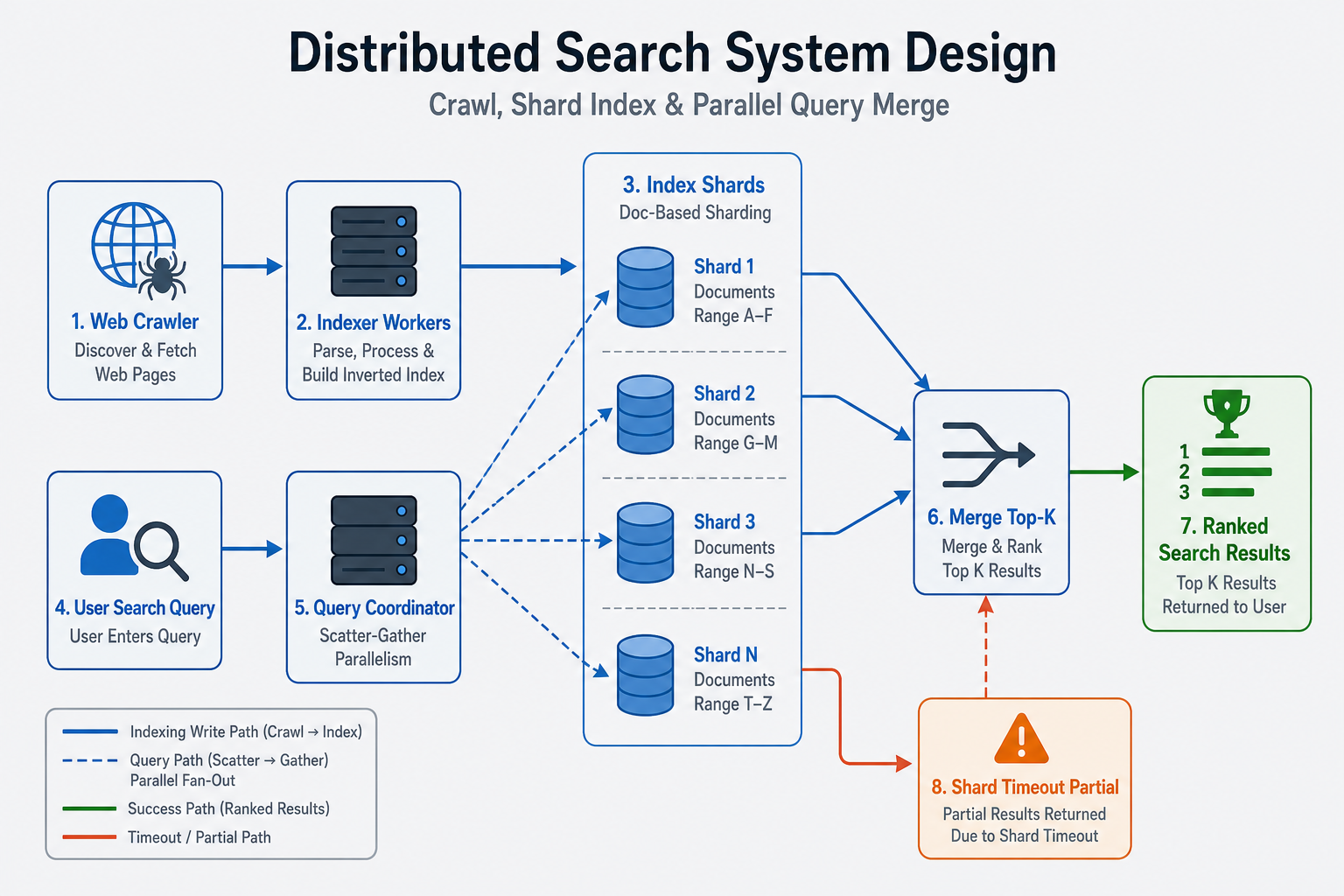
Scenario
Product catalog reindexes every night but shoppers expect findability within minutes of a new SKU—distributed inverted indexes, shard routing, and incremental updates beat one giant Elasticsearch on a single machine story.
Design a distributed search system for large document or product catalogs with full-text search, filters, and ranking. Focus on sharded inverted indexes and query coordination, not a single-node demo.
You should support indexing pipeline, search API, facets, and relevance ranking. Be ready to explain scatter-gather and incremental indexing.
Constraints
Index documents, full-text search, filters/facets, ranking, snippets, delete/update docs
< 200 ms p95 search, near-real-time indexing minutes, 99.9% availability
Billions documents, 10K QPS search, TB index size, hundreds of shards
Stages ahead
Log in to start practicing
Preview the problem below. Sign in to start your timed session, save progress, and use the AI coach.