Real Engineering Stories
The Monolith to Microservices Migration That Almost Failed
How to migrate from a monolith to microservices safely—plus a real incident where a big-bang cutover left orders and payments inconsistent.
This is a story about how we tried to migrate from a monolith to microservices and almost broke everything. It's also about why migrations are harder than building from scratch, and how we learned to migrate incrementally rather than all at once.
Related reading on this site: Planning a real cutover? Use a step-by-step monolith-to-microservices playbook with Steps 0–12, exit criteria, pitfalls, and checklists meant to sit beside this story. For local ACID, eventual consistency, transactional outbox, sagas, idempotency keys, and reconciliation when data spans services, see the consistency deep dive. For stable facades, routing phases, diagrams, and strangler-pattern failure modes, read the strangler guide.
Context
We were running a monolithic e-commerce application that handled orders, payments, inventory, and shipping. As we grew, the monolith became hard to scale and deploy. We decided to migrate to microservices.
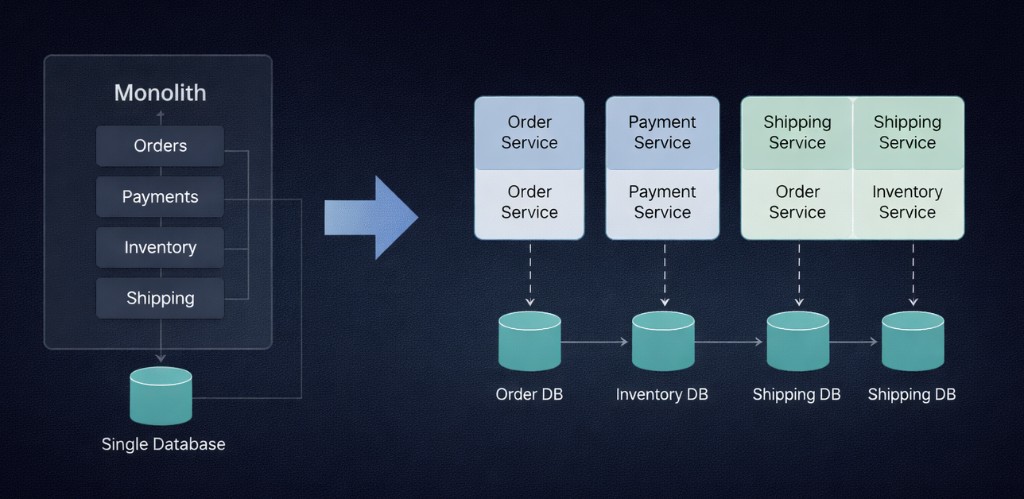
Monolith (shared database) versus split services with separate databases. Arrows between databases hint at the real work: keeping data consistent across boundaries.
Original Architecture:
Technology Choices:
- Monolith: Node.js application
- Database: PostgreSQL (single database for all services)
- Deployment: Single deployment unit
Assumptions Made:
- Microservices would be easier to scale
- Service boundaries were clear
- Data consistency would be maintained
- Each extracted service would own writes to its domain from day one—we skipped a transitional single-writer rule on shared tables
The Incident
Symptoms
What We Saw:
- Stuck Orders: Orders in "processing" state, never completing
- Data Inconsistency: Payments processed but inventory not reserved
- Service Dependencies: Services failing when dependencies were down
- Error Rate: Increased from 0.1% to 15%
- User Impact: ~100 orders in inconsistent state, manual intervention required
How We Detected It:
- Alert fired when order processing time exceeded threshold
- Dashboard showed orders stuck in "processing" state
- Service health checks showed inventory service down
Monitoring Gaps:
- No alert for data consistency issues
- No alert for service dependency failures
- No monitoring of distributed transaction state
Root Cause Analysis
Primary Cause: Service dependencies and data consistency issues in distributed system.
What Happened:
- Order service created order and called payment service
- Payment service processed payment successfully
- Payment service called inventory service to reserve items
- Inventory service was down (deployment issue)
- Inventory reservation failed, but payment already processed
- Order stuck in "processing" state
- No rollback mechanism for distributed transactions
- Data inconsistency: payment processed, inventory not reserved
Why It Was So Bad:
- Synchronous dependencies: Services called each other synchronously
- No transaction management: No distributed transaction coordinator
- No circuit breakers: Services kept calling failing dependencies
- No rollback mechanism: Couldn't undo partial operations
- Tight coupling: Services still tightly coupled despite separation
Contributing Factors:
- Migrated all services at once (big bang migration)
- No gradual migration strategy
- No distributed transaction management
- Services still had synchronous dependencies
- No fallback or compensation mechanisms
- Unclear data ownership during cutover—payment could commit while inventory reservation had no authoritative writer or compensating refund
How to migrate from a monolith to microservices (step by step)
The shorthand below is the same story you can read in expanded form with full steps, checklists, and guidance to avoid a big-bang cutover like this one.
Here is a practical playbook for how to migrate monolith to microservices in a way that survives production. The pattern is: narrow boundaries, move traffic in slices, untangle data on purpose, and treat cross-service workflows as distributed problems—not “the same code, more repos.” The timeline below is what strong teams aim for; the incident later in this article is what happens when you skip it.
1. Confirm you are solving the right problem
Microservices trade operational complexity for independent deploys and scaling. Before splitting, ask whether a modular monolith (clear modules, one deploy) or better team/process boundaries would fix the pain. Migrate when boundaries are clear and you can afford ownership, observability, and on-call per service.
2. Draw bounded contexts—not “layers”
Identify domains (e.g. orders, payments, inventory) with stable language and minimal chat across boundaries. Vertical slices (feature-sized extractions) beat splitting “all repositories” or “all controllers” first. Each slice should own its use cases end to end, not half a workflow.
3. Use the strangler fig pattern
Introduce a facade or API gateway in front of the monolith. Diagrams, lifecycle phases, and how a facade routes traffic without a big bang are spelled out in the strangler article. For one capability at a time:
- Route new or low-risk traffic to the new service.
- Keep the monolith as source of truth until the extracted service is proven.
- Expand the strangler until the old path is unused, then delete it.
Never decommission the monolith the same day you ship four new services—that is the failure mode this story illustrates.
4. Untangle data before you pretend you have “independent” services
Database-per-service is a target state, not day one. Typical progression:
- Shared database, separate schemas or clear table ownership (one writer per aggregate).
- Transactional outbox or CDC so other services learn about changes reliably without dual “guess and RPC.”
- Dual-write or backfill windows with reconciliation jobs when you must move rows.
- Freeze ambiguous writes; document who owns each entity’s lifecycle.
If two services synchronously call each other on the hot path for one business action, you often still have a distributed monolith—just slower.
5. Prefer asynchronous handoffs for multi-step business flows
Order → pay → reserve inventory is a workflow, not a stack of blocking HTTP calls. Model it with events, queues, or a saga (choreography or orchestration) with timeouts, retries, and compensating actions (e.g. refund, release reservation). Idempotency keys everywhere consumers can see duplicates.
6. Cut traffic with feature flags and measurable steps
Roll out with dark launch, canary, or percentage-based routing. Watch latency, error rate, saturation, and business metrics (e.g. stuck orders, payment success). One rollback lever per slice (toggle route back to monolith) beats “redeploy everything.”
7. Production checklist before you call the migration “done”
- SLOs and alerts per service and per dependency (including queues).
- Distributed tracing (correlation IDs across gateway → services → workers).
- Contract tests or consumer-driven contracts at API boundaries.
- Runbooks for partial failure (inventory down, payment timeout).
- Load tests on the new path, not only the old monolith.
At this point in the story, you have seen the failure path. Use this playbook as the practical migration plan for future cutovers, and map each step to the fixes in the next sections.
Fix & Mitigation
Immediate Fix:
- Rolled back to monolith: Restored previous architecture
- Fixed inconsistent orders: Manually resolved 100 stuck orders
- Restored service dependencies: Brought all services back online
Long-Term Improvements:
-
Gradual Migration Strategy:
- Migrated one service at a time (strangler pattern)
- Kept monolith running alongside microservices
- Gradually migrated traffic to microservices
- Decommissioned monolith only after all services stable
-
Event-Driven Architecture:
- Switched from synchronous to asynchronous communication
- Used message queue for service communication
- Implemented event sourcing for order state
- Added compensation mechanisms for failed operations
-
Data Consistency (patterns such as saga, outbox, and reconciliation are covered in cross-service consistency: ACID locally, eventual globally, operational safety nets):
- Implemented saga pattern for distributed transactions
- Added idempotency keys for operations
- Added eventual consistency with reconciliation
- Implemented two-phase commit for critical operations
-
Process Improvements:
- Added gradual migration to deployment process
- Added service dependency monitoring
- Created runbook for migration incidents
- Added rollback procedures for each service
Architecture After Fix
Key Changes:
- Event-driven architecture (async communication)
- Saga pattern for distributed transactions
- Gradual migration (strangler pattern)
- Service-specific databases
Key Lessons
-
Migrate gradually: Don't migrate all services at once. Use strangler pattern—migrate one service at a time, keep monolith running.
-
Use event-driven architecture: Synchronous service calls create tight coupling. Use message queues for loose coupling.
-
Handle distributed transactions: Use saga pattern or two-phase commit for data consistency across services.
-
Design for failure: Services will fail. Design compensation mechanisms and fallbacks.
-
Monitor service dependencies: Track service health and dependencies. Alert when dependencies fail.
Interview Takeaways
Common interview topics that have longer write-ups on this site: ordered steps and exit criteria for migrating off a monolith, keeping data trustworthy across services (outbox, sagas, idempotency, reconciliation), and incremental replacement behind a facade (strangler).
What Interviewers Are Looking For:
- Understanding of migration strategies
- Knowledge of distributed system patterns
- Experience with service boundaries
- Awareness of data consistency challenges
Quick answers to common follow-ups
How do you handle data consistency in microservices?
First, what is data inconsistency?
Data inconsistency means different services show different truths for the same business action at the same time. Example: payment says "charged" while inventory says "not reserved" and order says "processing."
Why this happens in microservices:
- Each service has its own database and commits locally.
- Cross-service updates happen through network calls or events.
- Failures, retries, timeouts, and out-of-order delivery can leave partial progress.
Why this is a problem:
- Users see confusing states (charged but no order confirmation).
- Finance and operations need manual cleanup.
- Reporting, support, and trust all degrade.
Use a layered approach:
- Inside one service: keep strong consistency with local ACID transactions.
- Across services: prefer eventual consistency with clear ownership of each aggregate.
- For business workflows: use saga pattern (choreography or orchestration) with retries, idempotency keys, and compensating actions.
- For critical edge cases: reserve stronger options (e.g. two-phase commit) only when strict consistency is worth the latency and availability cost.
- Operational safety net: run reconciliation jobs, detect drift, and alert on stuck workflow states.
Short interview line: Strong consistency locally, eventual consistency globally, and sagas for cross-service business flows.
For a longer treatment—layers from local ACID through outbox, sagas, idempotency, and reconciliation jobs—see the dedicated guide.
What is the strangler pattern?
The strangler pattern is an incremental migration strategy where a new service gradually replaces parts of a monolith behind a stable entry point (gateway/facade). Facade placement, phase-by-phase routing, diagrams, and mistakes that look like success are covered in the strangler article.
Typical flow:
- Keep the monolith live.
- Route one bounded capability to the new service.
- Shift traffic gradually with flags/canary.
- Delete the old monolith path only after stability and parity are proven.
Why teams use it: lower migration risk, easier rollback, and measurable progress instead of a risky big-bang rewrite.
What a Senior Engineer Would Do Differently
From the Start:
- Migrate gradually: Use strangler pattern, migrate one service at a time
- Use event-driven architecture: Async communication reduces coupling
- Implement saga pattern: Handle distributed transactions properly
- Design for failure: Add compensation and fallback mechanisms
- Monitor dependencies: Track service health and dependencies
The Real Lesson: Migrations are harder than building from scratch. Migrate gradually, use proven patterns, and always have a rollback plan.
How I'd answer in interviews
"We tried a big-bang monolith cutover—four services live in a week, monolith off Monday morning. A payment succeeded but inventory was down; with no saga or compensation, orders stuck in processing and we had about a hundred inconsistent rows. I'd never decommission the monolith until one slice at a time is proven behind a strangler facade: shadow traffic, canary ramp, clear data ownership with outbox or CDC, and async workflows with idempotency and reconciliation—not synchronous RPC chains on the checkout path."
FAQs
Q: How do you migrate from monolith to microservices?
A: Treat migration as a sequence of small releases, not one rewrite. The companion playbook walks Steps 0–12 with exit criteria, pitfalls, and checklists. (1) Bound domains (bounded contexts) and pick one vertical slice to extract first. (2) Put a strangler (gateway or facade) in front of the monolith and route a slice of traffic to the new service while the monolith remains authoritative where needed. (3) Clarify data ownership—shared DB only as a transitional step; use outbox/CDC and reconciliation when splitting storage. (4) Model multi-step flows with events or sagas, idempotency, and compensation, not long chains of synchronous RPC. (5) Canary or flag each step and keep rollback to the monolith path until metrics stay green. Decommission the monolith only when no critical traffic depends on it and on-call can own the new services.
Q: How do you handle data consistency in microservices?
A: Data inconsistency is when services disagree on one business action (for example, payment captured but inventory not reserved). Layers from local ACID through eventual consistency, outbox, sagas, idempotency, and reconciliation unpacks how teams run this in production. It happens because each service commits locally and cross-service work is asynchronous and failure-prone. Handle it with local ACID transactions per service, eventual consistency across services, sagas with retries/idempotency/compensation for workflows, and reconciliation jobs to detect and fix drift. Use stronger coordination (like 2PC) only for narrow, critical paths where the latency/availability trade-off is acceptable.
Q: What is the strangler pattern?
A: The strangler pattern is a migration strategy where you gradually replace a monolith by building new services alongside it, migrating functionality incrementally, and eventually decommissioning the monolith. Facades, traffic-shifting phases, diagrams, and common anti-patterns go deeper.
Q: Should you use synchronous or asynchronous communication between services?
A: Use both, but for different jobs. Use synchronous calls when the user needs an immediate answer in the same request (for example, auth checks or reading a profile needed to render the page). Use asynchronous communication for cross-service workflows and side effects (email, inventory updates, analytics, downstream fulfillment) so one slow dependency does not block the whole request path. In migration programs, the safest default is: keep the synchronous chain short and push non-critical steps to events/queues with retries and idempotency. If a synchronous hop is unavoidable, enforce strict timeouts, circuit breakers, and a clear fallback so one failing service does not take down everything.
Q: How do you handle distributed transactions?
A: Start by separating local transactions from cross-service workflows. Inside one service/database, use normal ACID transactions. Across services, use a saga (choreography or orchestration) with compensation, retries, timeouts, and idempotency keys; this is the practical default in most production systems. Reserve 2PC for narrow, high-criticality cases where temporary inconsistency is unacceptable and you can tolerate the latency/availability trade-off. Add reconciliation jobs and stuck-state alerts, because in distributed systems the real question is not only "can it fail?" but "how quickly can we detect and recover?"
Q: What are common migration pitfalls?
A: The biggest pitfall is treating migration as a rewrite project instead of a risk-managed sequence. Common failures are big-bang cutover, unclear service boundaries, and "microservices" that still share one database with multiple writers. Other frequent issues are long synchronous call chains, missing idempotency/compensation logic, weak observability (no end-to-end tracing), and no tested rollback path. Teams also underestimate organizational pitfalls: unclear ownership, cross-team deploy lockstep, and no runbooks for partial failure. A strong migration plan reduces risk per slice, not just code per repo.
Q: How do you test microservices migrations?
A: Test migrations in layers. First, run contract tests and compatibility tests at service boundaries so schema drift is caught before deployment. Then run shadow traffic (dark launch) to compare old vs new behavior on real request patterns without user impact. During rollout, use canary or percentage routing and monitor both technical metrics (latency, errors, saturation) and business metrics (order completion, payment success, stuck workflow counts). Finally, run chaos/failure drills (dependency down, timeout storms, duplicate event replay) and prove rollback works in minutes, not hours. If rollback is not rehearsed, it is not a rollback plan.
Keep exploring
Real engineering stories work best when combined with practice. Explore more stories or apply what you've learned in our system design practice platform.