Real Engineering Stories
The Race Condition That Only Happened in Production
A race condition in inventory checks caused overselling under flash-sale concurrency—impossible to reproduce until load exposed it.
This is a story about a bug that only happened in production, that we couldn't reproduce in testing, and that cost us money and customer trust. It's also about why concurrency bugs are so hard to find, and how we learned to think about race conditions from the start.
Related reading on this site: For transaction isolation and why SELECT-then-UPDATE is not atomic across requests, see Isolation Levels. For idempotency keys and safe retries when checkout spans multiple services, read Idempotency. For a sibling concurrency failure—locks acquired in the wrong order—see The Deadlock That Froze Our Payment System. When database load spikes from innocent reads, compare The N+1 Query Problem That Slowed Down Our API.
Context
We were running an e-commerce platform with an inventory management system. When customers purchased items, we needed to check inventory, reserve items, and update stock levels. The system handled about 1M purchase requests per day.
Original Architecture:
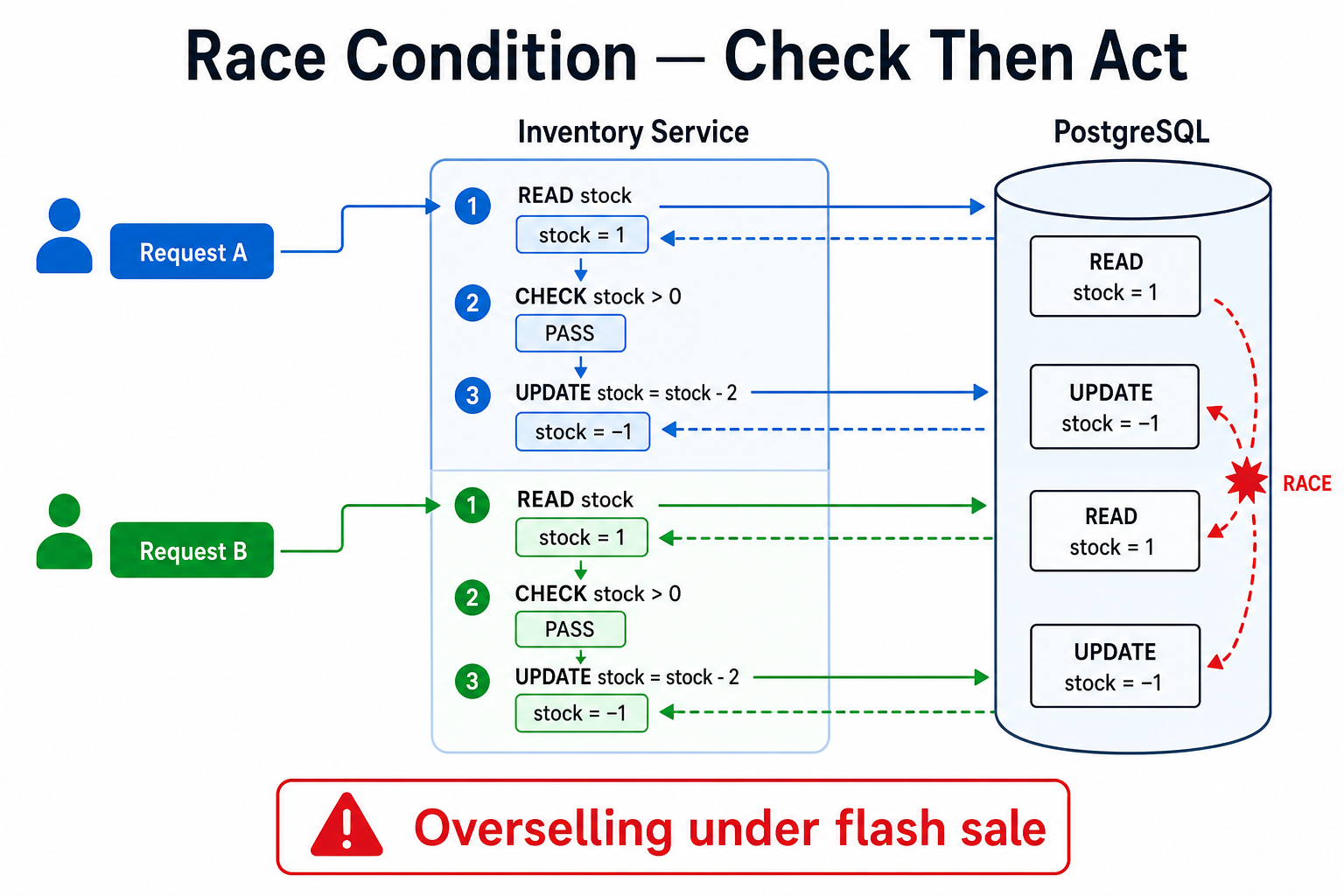
Check-then-act under flash-sale concurrency: both requests saw stock=1 and both decremented—inventory went negative.
Technology Choices:
- API: Node.js with Express
- Database: PostgreSQL with transactions
- Inventory Service: Node.js microservice
- Concurrency: Multiple API instances handling requests
Assumptions Made:
- Database transactions would prevent race conditions
- Inventory checks and updates would be atomic
- High concurrency wouldn't cause issues
The Incident
Symptoms
What We Saw:
- Oversold Items: 50 SKUs sold beyond available inventory over 7 days (1 → 5 → 20 reports before paging)
- Inventory Discrepancies: 12 rows hit negative stock (
stock < 0); hottest SKU went from 1 unit to −3 - Customer Complaints: ~50 customers charged successfully, then told "out of stock" on fulfillment
- Purchase Volume: ~1M requests/day; bug clustered on flash-sale SKUs with 200+ concurrent checkouts/minute
- Error Rate: 0% HTTP errors—payments succeeded while business invariants broke silently
- User Impact: Refunds, apology credits, and manual inventory reconciliation for a week
How We Detected It:
- Customer support reports of oversold items (lagging indicator)
- Weekly inventory audit surfaced negative stock levels
- Production logging (added Day 7) showed paired
SELECT stockcalls with identical timestamps before two successfulUPDATEs
Monitoring Gaps:
- No alert for
stock < 0or oversell rate - No metric for check-then-update gap duration (the 2s payment window)
- No distributed tracing across inventory check → payment → stock decrement
- No concurrency load tests in CI—staging never reproduced multi-instance races
Root Cause Analysis
Primary Cause: Race condition in inventory check and update—a classic check-then-act pattern across concurrent requests.
How check-then-pay turned the last unit into oversell:
Each purchase did three separate steps with no lock spanning them. Under low load, requests serialize naturally and the bug hides. Under flash-sale concurrency, two API instances can both read stock = 1, both pass the guard, both charge the card during the ~2s payment call, and both run UPDATE stock = stock - 1—ending at −1 with two fulfilled orders.
Request A: SELECT stock=1 ✓ → pay (2s) ─┐
Request B: SELECT stock=1 ✓ → pay (2s) ─┼→ both UPDATE → stock=-1 → 2 sales, 1 unit
The Bug:
// BAD CODE (simplified)
async function purchaseItem(userId, itemId, quantity) {
// Step 1: Check inventory (not locked)
const item = await db.query('SELECT stock FROM items WHERE id = ?', [itemId]);
if (item.stock < quantity) {
throw new Error('Insufficient stock');
}
// Step 2: Process payment (takes 2 seconds)
await processPayment(userId, itemId, quantity);
// Step 3: Update inventory (race condition here!)
await db.query('UPDATE items SET stock = stock - ? WHERE id = ?', [quantity, itemId]);
}
What Happened:
- Two requests arrive simultaneously for the last item in stock
- Both requests check inventory at the same time (both see stock = 1)
- Both requests pass the inventory check
- Both requests process payment (both succeed)
- Both requests update inventory (stock becomes -1)
- Result: Item oversold, negative inventory
Why It Was So Bad:
- No locking: Inventory check and update weren't atomic
- Payment before inventory update: Payment processed before inventory reserved
- High concurrency: Bug only appeared under load
- Impossible to reproduce: Required exact timing, couldn't test
Contributing Factors:
- No distributed locking mechanism
- Payment processing took 2 seconds (window for race condition)
- Multiple API instances handling concurrent requests
- No transaction isolation for inventory operations
Fix & Mitigation
Immediate Fix:
// FIXED CODE
async function purchaseItem(userId, itemId, quantity) {
// Use distributed lock to prevent race conditions
const lock = await acquireLock(`inventory:${itemId}`);
try {
// Check and update inventory atomically
const result = await db.query(
'UPDATE items SET stock = stock - ? WHERE id = ? AND stock >= ?',
[quantity, itemId, quantity]
);
if (result.affectedRows === 0) {
throw new Error('Insufficient stock');
}
// Process payment (inventory already reserved)
await processPayment(userId, itemId, quantity);
} finally {
await releaseLock(lock);
}
}
Long-Term Improvements:
| Strategy | What it does | Best when |
|---|---|---|
Atomic SQL (UPDATE … WHERE stock >= ?) | Check and decrement in one statement; affectedRows = 0 means sold out | Single-row inventory; lowest latency; no extra infra |
| Distributed lock (Redis/etcd) | Serializes all writers for a SKU across API instances | Multi-step checkout; payment gateway in the middle |
| Optimistic locking (version column) | Retry on version mismatch instead of blocking | Low contention SKUs; read-heavy catalog |
| Reserve-then-pay ordering | Decrement stock before charging; refund on payment failure | Prevent revenue on oversell; pairs with idempotency keys |
-
Distributed Locking:
- Implemented Redis-based distributed locks
- Added lock timeout to prevent deadlocks
- Added lock acquisition retry logic
-
Atomic Operations:
- Changed inventory update to atomic SQL (UPDATE with WHERE condition)
- Moved inventory check into update query
- Added optimistic locking with version numbers
-
Monitoring & Alerting:
- Added alert for negative inventory
- Added alert for oversold items
- Added logging of inventory operations
-
Process Improvements:
- Added concurrency testing to CI/CD
- Added load testing with race condition scenarios
- Created runbook for concurrency bugs
Architecture After Fix
Key Changes:
- Distributed locking for inventory operations
- Atomic SQL updates (check and update in one query)
- Inventory reserved before payment
- Lock monitoring and alerting
Key Lessons
-
Race conditions are timing-dependent: They only appear under specific concurrency conditions, making them hard to reproduce and test.
-
Use distributed locks: For distributed systems, use distributed locks (Redis, etcd) to prevent race conditions across instances.
-
Make operations atomic: Use atomic SQL operations (UPDATE with WHERE) instead of check-then-update patterns.
-
Reserve before processing: Reserve inventory before processing payment, not after. This prevents overselling.
-
Test under load: Race conditions only appear under high concurrency. Load test with concurrent requests.
Interview Takeaways
Common Questions:
- "What is a race condition?"
- "How do you prevent race conditions?"
- "How do you debug production-only bugs?"
What Interviewers Are Looking For:
- Understanding of race conditions and concurrency
- Knowledge of distributed locking mechanisms
- Experience with debugging production issues
- Awareness of atomic operations
What a Senior Engineer Would Do Differently
From the Start:
- Use atomic operations: UPDATE with WHERE condition instead of check-then-update
- Add distributed locks: Use Redis locks for critical sections across instances
- Reserve before processing: Reserve inventory before payment, not after
- Add logging: Log all inventory operations to debug race conditions
- Test under load: Load test with concurrent requests to catch race conditions
The Real Lesson: Race conditions are invisible until they're not. Design for concurrency from the start—use locks, atomic operations, and test under load.
How I'd answer in interviews
"We had a check-then-update inventory path: SELECT stock, process payment for two seconds, then UPDATE. Under flash-sale concurrency two requests both saw stock equals one, both paid, and both decremented—ending negative with no HTTP errors. I'd fix it by reserving stock first with an atomic UPDATE WHERE stock is at least quantity, or a per-SKU distributed lock across API instances, then charging only after a successful decrement. I'd alert on negative inventory, trace the check-to-update gap, and load-test multi-instance races in CI—not just single-threaded unit tests."
Related reading on this site
- Isolation Levels — why default READ COMMITTED does not make your application logic atomic across requests.
- Idempotency — safe retries when reserve-then-pay spans payment and inventory services.
- The Deadlock That Froze Our Payment System — another concurrency failure when locks span multiple resources.
- Deadlock Conditions & Prevention — lock ordering and timeout patterns that pair with distributed locks.
- The N+1 Query Problem That Slowed Down Our API — different failure mode, same lesson: production load exposes assumptions tests miss.
FAQs
Q: What is a race condition?
A: A race condition occurs when the outcome depends on the timing of events. Two or more operations access shared data concurrently, and the result depends on which operation completes first.
Q: How do you prevent race conditions?
A: Use locks (distributed locks for microservices), atomic operations (SQL UPDATE with WHERE), or transactional isolation. Design operations to be atomic from the start.
Q: Why are race conditions hard to reproduce?
A: Race conditions depend on exact timing of concurrent operations. They only appear under specific concurrency conditions, making them hard to reproduce in testing.
Q: How do you debug production-only race conditions?
A: Add extensive logging, use distributed tracing, monitor for patterns (like negative inventory), and use load testing to reproduce the conditions.
Q: Should you always use locks?
A: Not always. Locks add latency and complexity. Use atomic operations when possible, locks when necessary. Consider optimistic locking for low-contention scenarios.
Q: What's the difference between a race condition and a deadlock?
A: A race condition is when operations interfere with each other because timing decides the outcome. A deadlock is when operations wait for each other indefinitely. Both are concurrency problems but different failure modes.
Q: What's the difference between a distributed lock and a database transaction?
A: A database transaction atomizes SQL statements in one connection—it does not span your payment API call unless you hold the transaction open (bad for latency). A distributed lock serializes the whole business operation across services and instances. Use atomic SQL when one row suffices; use distributed locks when checkout spans multiple steps or services.
Q: How do you test for race conditions?
A: Load test with concurrent requests, use chaos engineering to introduce timing variations, and add logging to detect race condition patterns. Consider formal verification for critical systems.
Keep exploring
Real engineering stories work best when combined with practice. Explore more stories or apply what you've learned in our system design practice platform.