Real Engineering Stories
The Database Failover That Didn't Fail Over
Primary PostgreSQL OOM-killed; Patroni refused replica promotion at 45s lag—untested failover caused a 90-minute outage.
This is a story about the night we learned our "high availability" PostgreSQL cluster was theory on a slide deck. At 2:14 AM, the primary OOM-killed under a runaway analytics query. Patroni tried to promote Replica 1—refused: 45 seconds of replication lag (data-loss threshold: 10s). Replica 2 failed sync_check—async replica missing WAL. Result: no writable database for 90 minutes, 100% API error rate, and ~1.2M failed requests until we manually revived the primary.
The lesson: if you haven't tested failover in the last quarter, you don't have HA—you have hope.
Related reading on this site: For replication, RPO/RTO, and consistency trade-offs, see Databases and Disaster Recovery. For pool exhaustion during the outage, read Database Connection Pooling. For monitoring gaps, see Monitoring & Observability. For a sibling cache-layer cascade, compare The Cache Stampede That Took Down Our API.
Context
We ran a SaaS API on PostgreSQL 14 with Patroni + etcd for automatic failover. The cluster: one primary, Replica 1 (synchronous replication), Replica 2 (async, read scaling). Daily traffic ~18M requests; nightly ETL plus ad-hoc analytics queries spiked read load on replicas.
Original Architecture:
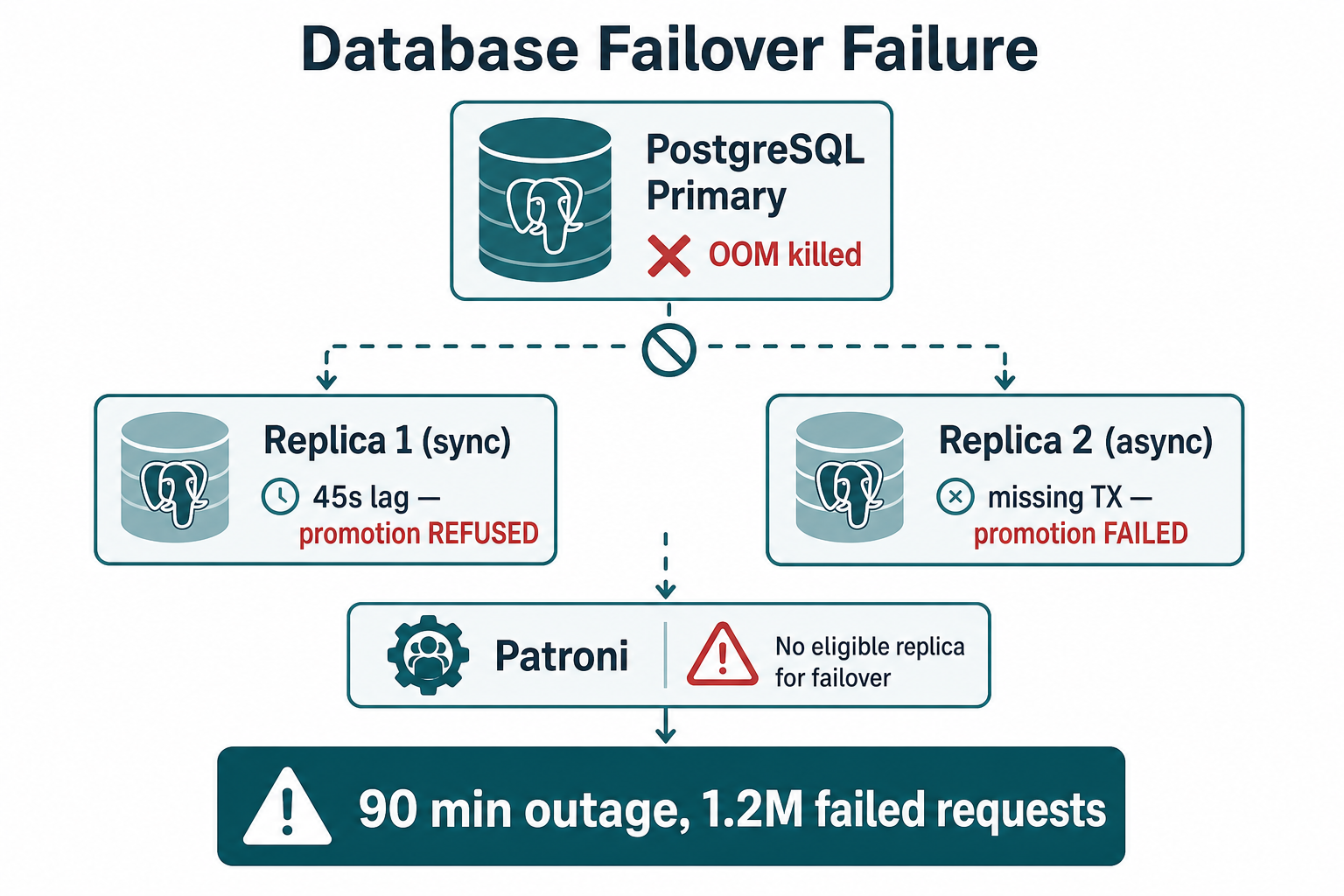
We had two replicas on paper—neither was promotable when the primary died at 2:14 AM.
Technology Choices:
- HA: Patroni 3.x, etcd 3-node cluster,
synchronous_commit = onto Replica 1 - Replication: Streaming replication; lag alert threshold 10 seconds (never fired in prod)
- Failover policy: Promote sync replica if lag < 10s; refuse promotion otherwise
- Last failover test: 18 months ago, manual, during planned maintenance—never automated chaos
Assumptions Made:
- Failover would work the first time we needed it
- Sync replica was always within 10s of primary (true until it wasn't)
- Async Replica 2 was a failover backup (it wasn't configured for promotion)
- Patroni config hadn't drifted since initial setup
The Incident
Symptoms
What We Saw:
- API error rate: 0.1% → 100% in 30 seconds (all DB connection errors)
- PgBouncer: 200/200 connections busy; 4,800 clients queued
- Replication lag (Replica 1): 45 seconds at failover moment (alert threshold 10s—alert silenced for maintenance window)
- Patroni logs:
not promoting because lag too big, thensync_check failedon Replica 2 - Failed requests: ~1.2M during 90-minute window (includes client retries)
- User impact: Complete write outage; reads on Replica 2 served stale data until taken offline
How We Detected It:
- PagerDuty: API error rate > 5% (fired at 2:16 AM)
- Patroni REST API showed
master: none—no leader elected pg_is_in_recovery()true on all surviving nodes
Monitoring Gaps:
- Replication lag alert muted for "maintenance" that wasn't happening on DB
- No weekly automated failover validation
- No alert when Patroni cannot elect a leader for > 60 seconds
- Dashboard didn't show which replica was promotion-eligible
Root Cause Analysis
Primary Cause: Automatic failover could not promote any replica—sync replica lag exceeded safety threshold; async replica was never validated for promotion.
Mechanism chain:
- Long-running analytics query on primary consumed memory; OS OOM killer terminated
postgreson primary. - Patroni detected primary failure and evaluated Replica 1 (sync standby).
- Replica 1 had fallen 45 seconds behind—heavy read queries on the replica slowed WAL apply;
max_data_losswas 10 seconds → promotion refused to prevent data loss. - Patroni fell through to Replica 2 (async)—Patroni config assumed sync path;
sync_checkfailed because async replica lacked recent WAL. - Failover script bug: role mapping hardcoded
replica-1as only promotion target—Replica 2 path untested for 18 months. - Manual recovery: restart primary host, wait for crash recovery + replication catch-up—90 minutes total.
Primary OOM → Patroni failover → sync replica lag 45s > 10s threshold → async replica unfit → no leader → full outage
Why It Was So Bad:
- Failover never tested after config changes 18 months prior
- Replication lag treated as informational until it blocked promotion
- Async replica falsely counted as DR target without acceptance of data loss
- Analytics on primary—the OOM trigger was preventable
Contributing Factors:
- Maintenance window silenced lag alerts incorrectly
- Replica CPU at 88% during nightly jobs—apply lag grew quietly
- No
pg_cancel_backendautomation for runaway queries - Runbook assumed auto-failover always succeeds
Fix & Mitigation
Immediate Fixes (During Incident):
- Manual primary restart on same hardware after OOM (2:45 AM)
- Took Replica 2 offline from read pool to stop serving stale reads
- Killed analytics job and moved it to Replica 2 post-recovery
- Increased
max_data_losstemporarily—reverted after lag controls in place (documented trade-off)
Long-Term Improvements:
| Strategy | What it does | Best when |
|---|---|---|
| Monthly failover drills | Chaos-kill primary in staging; quarterly in prod off-peak | Any Patroni/k8s HA setup |
| Tight lag alerting | Warn 1s, page 5s—never mute without ticket | Sync failover dependencies |
| Dedicated analytics replica | Isolate heavy reads from sync standby | Nightly ETL + HA promotion path |
| Runaway query guard | statement_timeout, pg_cancel_backend, OOM-aware limits | Shared OLTP + analytics |
| Promotion eligibility dashboard | Show lag, sync state, last successful drill | On-call triage |
| Documented manual failover | Tested quarterly with RPO/RTO measured | When auto-failover refuses promotion |
- Monthly automated failover test in staging; quarterly prod drill with executive sign-off
- Replication lag alerts: warning at 1s, page at 5s—no silent muting
- Replica 1 dedicated to sync HA only—analytics moved to Replica 3 (async)
- Patroni config fix: explicit promotion candidates, tested async promotion with accepted RPO
- Statement timeout 120s on primary for ad-hoc queries; analytics role restricted to replica
- Leader election alert: page if no Patroni leader for 60 seconds
Architecture After Fix
Replica 1 is reserved for synchronous HA only; analytics and read scaling move to separate nodes so promotion eligibility stays predictable.
Key Changes:
- Sync replica isolated from heavy read/analytics load
- Monthly failover drills with measured RTO/RPO
- Lag alerting that pages before promotion threshold
- Runaway query controls on primary
- Patroni promotion paths tested for both sync and documented async break-glass
Key Lessons
-
Untested failover is not HA—drills reveal config drift, script bugs, and wrong assumptions.
-
Replication lag is a promotion gate—monitor it like uptime, not like a nice-to-have graph.
-
Async replicas are not failover replicas unless you accept data loss and test promotion.
-
Don't run analytics on the primary—OOM on the writer kills the entire cluster's write path.
-
Alert muting needs discipline—silencing lag alerts during a non-DB "maintenance" masked the real risk.
-
Measure RTO/RPO in drills—our runbook said "minutes"; reality was 90 minutes.
-
Have a manual break-glass path—when auto-failover refuses, on-call needs tested steps, not hope.
Interview Takeaways
Common Questions:
- "How do you test database failover?"
- "What causes a replica to be unfit for promotion?"
- "Sync vs async replication for HA?"
What Interviewers Are Looking For:
- RPO/RTO trade-offs when promotion is refused due to lag
- Difference between read replicas and failover candidates
- Chaos engineering and quarterly drills
- Replication lag causes (read load slowing apply)
What a Senior Engineer Would Do Differently
From the Start:
- Monthly failover drill with documented RTO/RPO from day one
- Dedicated sync standby—not shared with heavy read traffic
- Lag alerts at 1s/5s tied to promotion thresholds
- Statement timeouts and query routing for analytics
- Leader-election monitoring—page when Patroni has no master
The Real Lesson: HA systems rot. Config drifts, traffic patterns change, and scripts rust. Test failover constantly—or admit your RTO is "however long manual recovery takes."
How I'd answer in interviews
"We had Patroni with a synchronous replica, but under load the replica fell forty-five seconds behind—when the primary OOM-killed, Patroni refused promotion past our ten-second data-loss limit. The async read replica wasn't promotion-ready either; we hadn't tested failover in eighteen months. I'd run monthly chaos drills, alert on replication lag at one and five seconds, isolate the sync standby from analytics reads, add statement timeouts on the primary, document a manual break-glass with measured RPO, and treat async replicas as read scale-out unless we explicitly accept data loss and test that path."
Related reading on this site
- Databases — replication modes, consistency, and promotion trade-offs.
- Disaster Recovery — RTO/RPO, backup vs failover, restore testing.
- Database Connection Pooling — queueing and timeouts when the database disappears.
- Monitoring & Observability — SLOs, alert design, and avoiding silent muting.
- The Cache Stampede That Took Down Our API — another cascade when the data layer can't serve load.
FAQs
Q: Why didn't Patroni promote the sync replica?
A: Replication lag was 45 seconds—above our configured max_data_loss of 10 seconds. Patroni correctly refused to avoid promoting a stale copy.
Q: Can we use an async replica for failover?
A: Only if you accept data loss (higher RPO), configure Patroni for that path, and test it. Async replicas optimize read scaling—not HA by default.
Q: How often should you test failover?
A: Monthly in staging, quarterly in production (off-peak), plus after any Patroni/etcd/PostgreSQL upgrade. Record actual RTO/RPO each time.
Q: What replication lag is acceptable?
A: For sync HA promotion, aim for sub-second lag under load. Alert at 1s warn / 5s page—not 10s after the fact.
Q: What's the difference between failover failure and a slow primary?
A: Failover failure means no new leader—writes are impossible. A slow primary still accepts writes but latency spikes. Different alerts, different runbooks.
Q: Why did read load on Replica 1 affect lag?
A: Heavy queries on a standby compete for I/O and CPU with WAL replay. Apply slows → lag grows → promotion threshold breached.
Q: Should we lower max_data_loss to force promotion?
A: Lowering the threshold increases refusal risk—it doesn't fix lag. Fix apply performance and isolate the sync standby; don't paper over lag with risky promotion.
Keep exploring
Real engineering stories work best when combined with practice. Explore more stories or apply what you've learned in our system design practice platform.