System design interview guide
Facebook Feed System Design
Your friend posted ten minutes ago but your feed still looks like yesterday—fan-out lag or ranker timeout is the product failure. Hybrid fan-out, celebrity policy, and degraded ranking are what interviewers grade.
Problem statement
Home feed: publish, hybrid fan-out, ranking, celebrity scale.
Introduction
You open the app after lunch. Your friend posted a photo ten minutes ago, but your feed still looks like yesterday. You pull to refresh. Nothing changes. The post “succeeded” for them—your timeline is just behind.
That feeling is the product. The interview is the machinery: reads crush writes, a few accounts have massive follower counts, and any design that does unbounded work per swipe or fans out every post to everyone breaks in cost and tail latency before it breaks on the whiteboard.
Interviewers are not grading box count. They want three ideas in plain language:
- Push vs pull vs hybrid — where you pay cost on publish vs on scroll.
- Split storage — feed rows are IDs and order; post bodies and media live elsewhere.
- Honest fuzz — ranking moves, graphs change, pagination will duplicate or skip sometimes.
Weak answers draw Kafka with no celebrity policy. Strong answers walk one write and one read and name what degrades when the fan-out queue or ranker lags.
If you remember one thing: The home feed is a bounded read path over precomputed candidates—not one giant join on every scroll.
How to approach
Treat the first minutes as a negotiation, not a quiz.
Ask what “feed” means (home only vs groups). Ask if ranking is in scope. Ask what fresh means in seconds—chronological vs “Top stories” changes your whole story.
Then do one capacity pass: reads vs writes, fan-out for a normal user vs a celebrity, and where fire starts (mailbox shards, fan-out queue, ranker).
Walk one write: post durable → async fan-out (idempotent). Walk one read: candidates → batch bodies → filter blocks → rank under budget → cursor.
If time is short, prioritize celebrity policy and pagination when rank moves—those separate template answers from production thinking.
In the room: “I’ll scope home vs ranking, estimate read:write skew, then narrate one post publish and one feed page before naming stores.”
If you remember one thing: One write, one read—then storage brands.
Interview tips
Five exchanges that show up on almost every feed interview. Each block: what you might say, what they push on, where to land.
Fan-out on write only
You: “When someone posts, we fan out to every follower’s mailbox.”
They ask: “A page with 50 million followers hits Post—what happens to your queue and storage?”
Land here: Hybrid policy: push for the long tail where fan-out is cheap; for mega-followed authors, merge on read, partial fan-out to active users, or store by author and intersect at scroll time. Name queue depth and blast radius, not “we use Kafka.”
Where post bodies live
You: “The feed service stores everything in one database.”
They ask: “What travels on every scroll—full post JSON or pointers?”
Land here: Mailbox / timeline store holds ordered post IDs (or score+id) per viewer, sharded by user_id. Post service + object storage + CDN own bodies and media. Feed path multi-gets by id and caps work.
Ranking as one box
You: “We call the ML service and sort.”
They ask: “Ranker p99 doubles—does the whole app hang?”
Land here: Separate candidate generation (bounded list of IDs) from scoring. Hard timeout on rank; fallback to recency or last good slice. Circuit breaker so the edge does not block on one dependency.
Pagination with moving order
You: “We use offset and limit—page 2 is easy.”
They ask: “Scores change between requests—do users see duplicates or gaps?”
Land here: Opaque cursor or (score, post_id) continuation; admit best-effort stability—rare dup/skip, not fake strong consistency. Weak answers pretend offset pagination scales.
Blocks and unfollows
You: “We delete all feed rows when someone unfollows.”
They ask: “At a billion edges, can you recompute every mailbox synchronously?”
Land here: Graph updates are eventual; filter blocks at read for safety; TTL, lazy filter, or compensating deletes for stale IDs. Brief staleness on unfollow is OK; block paths are not.
If you remember one thing: After each push, name one mechanism—hybrid fan-out, idempotent (viewer_id, post_id), ranker timeout, cursor—not “we’ll scale it.”
Capacity estimation
Rough numbers to anchor the whiteboard (tune in the room):
| Input | Order of magnitude |
|---|---|
| DAU | 500M+ (from problem spec) |
| Home feed reads per DAU | Tens to hundreds per day (people open the app often, not every scroll is a full refetch) |
| Writes (new posts) per day | Hundreds of millions globally → write QPS is modest vs read QPS |
| Follow graph | Highly skewed: median user hundreds of follows; P99 and celebrities dominate cost |
Implications: You cannot do O(followers) work on every read. You shard mailboxes or cap pull-merge. You async fan-out. You bound candidate pools before ranking so p95 stays in range.
If you remember one thing: Numbers exist to show skew—reads dominate, celebrities break naive fan-out.
High-level architecture
At a whiteboard, you need a story, not a catalog. One reasonable story: traffic hits edge + API (TLS termination, auth, rate limits, request IDs); a feed service owns “give me the next page of the home timeline”; it pulls candidate post IDs from per-user storage (mailboxes and/or on-read merge), batch-loads post bodies and author metadata, applies safety filters (blocks, policy), then hands a bounded candidate set to a ranker with a hard time budget. Nothing in that sentence assumes a single database or a monolith—only clear ownership of each hop.
Who owns what (typical split):
- API / BFF — Session or token validation, coarse routing, timeouts to downstreams, sometimes response shaping so the mobile client is not fanning out to twenty microservices.
- Feed service — Orchestrates read path: assemble candidates, call graph for “who can this viewer see?”, call post store for bodies, call ranker, return cursor + hydrated posts. It is where you cap work (max candidates, max fan-out depth).
- Mailbox / timeline store — Durable ordered lists of post IDs (or score+id tuples) per viewer, often sharded by
user_id. This is not the full post body store. - Post service + object storage — Source of truth for post metadata (author, created_at, privacy, media keys). Blob/video live in object storage; CDN serves bytes; URLs in API responses are usually signed or stable ids resolved at read time.
- Graph service — Follow / unfollow / block / mute edges; heavily cached at the edge of the feed path because every home read touches it.
- Fan-out workers — Consumers off a queue or log: given
(post_id, author_id), append to follower mailboxes where push is in policy. Work is at-least-once; writes are idempotent(viewer_id, post_id)so retries do not duplicate. - Ranker / scoring — May be embedded in feed svc or separate; often feature/log fetches first, then score. Treat it as best-effort within SLA, not a synchronous join to every offline job.
Where caching sits: Hot post bodies, author profiles, and graph “following set” snapshots are common cache layers—often between feed orchestration and the durable stores. Say what is safe to serve stale (profile display name) vs not (block list for safety).
Celebrity / hybrid on the diagram: For authors you do not fully fan out, the feed service still merges recent posts by author id (or pulls from an author-indexed store) into the candidate pool. Label that edge on the whiteboard—otherwise the diagram only shows push fan-out and you get the follow-up you deserve.
[ Client ]
→ [ LB / API gateway ] → [ Feed svc ] → [ Cache? ] → [ Mailbox store / merge ] → [ Ranker ] → response
↑ ↑
| +-- optional: recent-tail / author merge (hybrid)
|
[ Graph svc ]--+ (follows, blocks)
|
[ Post svc ] ←---------+ (metadata, not media bytes)
|
+→ [ Fan-out queue ] → workers → mailboxes (per-viewer timeline shards)
|
+→ [ Object store ] → [ CDN ] (media)
In the room: Narrate the read path first (latency budget, bounded candidates, ranker timeout). Then one write (durable post → async fan-out → idempotent mailbox writes). Interviewers often let you fill in storage brands once they believe you will not fan-out 100M rows on every post.
If you remember one thing: Read path is IDs → batch hydrate → rank with timeout; write path acks before every mailbox row exists.
Core design approaches
Fan-out on write (push)
After a post is stored, push its ID into each follower’s mailbox (per shard). Reads feel cheap because the heavy work already happened.
The catch is the O(followers) wall. The moment you say “we fan out to everyone,” you owe the room a celebrity exception—or you have accidentally designed a distributed denial-of-service machine that charges you money.
Pull on read
At request time, pull recent posts from followed accounts and merge. That dodges the celebrity write blast, but you can spend a lot of CPU merging wide fan-in if someone follows thousands of accounts—so real systems cap, cache, or hybridize.
Hybrid (what production usually sounds like)
Push for the long tail where fan-out is cheap. For mega-followed authors, do not materialize every edge—merge their recent posts on read, or fan-out only to “active” mailboxes, or store by author and intersect. The exact policy matters less than saying there is a policy and naming the cost driver (queue depth, storage, blast radius).
If you remember one thing: Hybrid is the real answer—pure push or pure pull alone fails at scale.
Detailed design
Write path
Walk it like you are explaining an outage retro: media lands in object storage; the post row gets durable metadata; the client gets success without waiting for every follower’s mailbox row. Fan-out runs as async work with idempotency so retries do not duplicate (post_id → mailbox) inserts.
Everything else—search indexing, notifications, ugly link previews—can trail behind. If you put those on the critical path, you will miss latency and still get the wrong Open Graph image sometimes.
Read path
This is the path that actually matters for “how does Facebook feel fast?” Load a chunk of candidate IDs for the viewer (precomputed + optional recent tail if you hybridize), multi-get bodies and authors, filter blocks and hard safety rules, then rank under a time budget and return a cursor that survives the next request.
If you only say “we call the ML service,” follow up with what you do when ML is slow—because that is what your on-call cares about.
If you remember one thing: Post 201 means durable metadata; followers see it when fan-out + read path catch up—not in the same millisecond for everyone.
Key challenges
- Skew: One author, 100M followers—fan-out on write is a storage and queue blast radius.
- Pagination vs ranking: Order changes between requests; cursors and occasional dup/skip are expected—don’t fake strong consistency.
- Graph churn: Unfollow/block must become visible without infinite recomputation—TTL, lazy filter, compensating deletes.
- Ranking lag: Scores can be seconds stale; product and safety need explicit contracts.
If you remember one thing: Skew picks fan-out policy; moving rank picks cursor honesty.
Scaling the system
Caching is not a vibe; it is a list of keys that catch fire. Hot posts, hot profiles, and “everyone requests the same post ID at once” are where you add request coalescing and TTL jitter. Sharding is usually mailboxes by user_id, posts by id or author-time, and no joins on the hot read path.
Multi-region is almost always “read mostly local, accept some staleness, replay fan-out idempotently”—if you claim one global strongly consistent view of every mailbox, you will get a skeptical follow-up.
If you remember one thing: Scale reads with sharded mailboxes + CDN; scale writes with async fan-out + caps—not bigger SQL joins.
Bottlenecks and tradeoffs
Precompute vs read-time merge
The tension — Materializing every follower’s mailbox makes scroll fast; celebrities make write amplification impossible.
What breaks — Fan-out queue depth explodes; one post fans out to tens of millions of rows.
What teams do — Hybrid: push for normal accounts, merge on read or author-indexed tails for the head; alert on queue age and per-shard backlog.
Say in the interview — Name who you fan out to and who you merge at read—not “we fan out.”
Fresh ranking vs stable pagination
The tension — Users want relevant order; cursors want stable continuation.
What breaks — Duplicates or skips when scores shift between page loads.
What teams do — Opaque cursors, session snapshots for experiments, client-side dup skip; admit best-effort.
Say in the interview — Offset/limit at scale is a trap; cursor + honesty beats fake consistency.
Cost vs freshness
The tension — More precomputed mailboxes smooth reads; they cost storage and fan-out CPU.
What breaks — Thin mailboxes push merge work into p99 read when someone follows thousands of accounts.
What teams do — Cap candidates before rank; TTL trim on mailboxes; tier storage for cold tails.
Say in the interview — Pick what you buy with money: storage or read CPU.
If you remember one thing: Every feed tradeoff is where you pay—publish, scroll, or ops when queues lag.
Failure handling
- Ranker slow or down: Timeout; fall back to recency-only slice; feature flag off heavy models.
- Fan-out backlog: Still show read path from existing mailboxes + pull-merge; alert on queue age, shed load.
- Cache miss / stampede: TTL jitter, singleflight for hot post IDs.
- DB degraded: Circuit-break; serve stale but safe feed rather than empty 500s where product allows.
If you remember one thing: Degrade the feed (recency, stale slice)—do not block the edge behind a slow ranker.
API design
Illustrative REST-style surface (GraphQL is fine if you name batching, N+1 avoidance, and field cost—feeds are exactly where naive graphs hurt).
Core resources: posts, users, me/home (collection = feed page). Version the path (/v1/) so you can deprecate fields without breaking every client.
POST /v1/posts
GET /v1/me/home
GET /v1/posts/{post_id}
POST /v1/users/{user_id}/follow
DELETE /v1/users/{user_id}/follow
POST /v1/posts/{post_id}/reactions # optional in scope
GET /v1/posts/{post_id}/comments # optional; often cursor-paged
POST /v1/posts/{post_id}/comments
Home feed — GET /v1/me/home
| Query param | Role |
|---|---|
cursor | Opaque continuation from last response (preferred) or compound (score,post_id) if you must spell it |
limit | Page size (cap server-side, e.g. ≤ 50) |
ranking | top | recent (product mode; may change candidate source + ranker) |
session_id | Optional, for session-scoped snapshot / experiments |
Response sketch: { "items": [ Post ], "next_cursor": "...", "has_more": true }. Each Post embeds or references author, media URLs or placeholders, counts (reactions/comments), and client tokens for ranking debug only if you want to argue observability.
Errors: 401 unauthenticated; 429 with Retry-After when throttled; avoid leaking whether a blocked user exists—use generic 404/403 per product policy.
Create post — POST /v1/posts
- Headers:
Idempotency-Keyfor safe retries (same key → samepost_id, no duplicate stories). - Body: text, link URL,
media_ids[]already uploaded via separate upload URLs (multipart to object storage is common—do not put 4K video bytes in JSON). - Success:
201+Location: /v1/posts/{id}; body includescreated_atand processing state (media_ready: pending/ready).
Follow graph
POST / DELETE on /v1/users/{id}/follow return 204 or 200 with updated counts. Graph updates are eventually visible in feed—say so if asked.
Reactions / comments (if in scope)
Prefer nested routes under the post for clarity and cache keys: POST /v1/posts/{id}/reactions with { "type": "like" }. Comments page the same way as the feed: cursor + limit, same duplicate/skip story when new comments arrive during scroll.
Cross-cutting behavior to name in the interview
- Rate limits: Per-user and per-IP on create and follow; return
X-RateLimit-Remainingif you want extra credit. - Pagination contract: Document whether
next_cursoris opaque (ranker-issued) or structured; either is fine if you explain moving ranks and dupes. - Versioning & mobile: Older app versions may send
Accept-Featureor aclient_versionquery—only if you have time; otherwise acknowledge backward-compatible field additions.
In the room: Spend one minute on idempotency for
POST /v1/posts, cursor semantics forGET /v1/me/home, and why reactions are not on the critical path for feed p95—that is enough to sound like you shipped APIs, not that you memorized a table.
Production angles
Dashboards can look green while the feed feels stale. Post create returns 201. The pain is queue age, ranker p99, and one viral post_id melting cache—not a wrong ER diagram.
Fan-out backlog while posts “succeed”
What users saw — A celebrity or live event posts; friends refresh and still see old ordering. Posting still works; the new story is “missing” for minutes.
Why — Fan-out is async. Workers append (post_id, author_id) to mailboxes at finite speed. When queue depth or per-shard backlog grows, time-to-visible grows even though the write path returned success.
What good teams do — Alert on consumer lag and queue age, not only API 200 rate. Cap fan-out per tick; lean on read-side merge while the queue drains; priority lanes for “last hour” vs full history. Name the metric that goes red first.
Ranker deploys and thread exhaustion
What users saw — Feed spinners; unrelated API routes slow; mobile feels “stuck” after a ranking deploy.
Why — Ranker sits on the hot path unless isolated. Missing timeout lets the gateway thread pool fill waiting on one dependency.
What good teams do — Hard rank timeout; circuit breaker; recency fallback; kill switch for heavy models. Separate SLOs: feed loads vs perfect rank.
Partial fan-out and “I see it, you don’t”
What users saw — Coworkers in different regions disagree whether a big post appeared; one refreshes and sees it, one does not.
Why — Global fan-out is not one synchronous transaction. At-least-once workers plus regional shards mean eventual visibility.
What good teams do — Idempotent mailbox writes; dedupe keys; dashboards on cross-region lag. Do not promise instant worldwide materialization in the interview.
Cache stampede on a hot post ID
What users saw — One viral post; feed still loads but p99 spikes; database or post service catches fire while “cache hit ratio” looks fine.
Why — Every scroll multi-gets the same post_id. TTL expiry without jitter aligns thousands of misses at once.
What good teams do — Singleflight per key; TTL jitter; stale-while-revalidate; in-process micro-cache for hottest IDs. Watch origin QPS on one key, not cluster average CPU.
How to use this in an interview — Pick one story: queue lag, ranker timeout, or stampede. Name one metric and one mitigation. Explain why post 201 and stale feed can happen together.
What should stick
You do not need to memorize every box. After this guide, you should be able to:
- Read:write skew — Almost everyone scrolls; few post; celebrities break naive fan-out.
- Hybrid fan-out — Push where cheap; merge or pull for the head; policy by follower count.
- IDs vs bodies — Mailboxes hold order; posts and media live elsewhere; batch hydrate.
- Ranker is best-effort — Bounded candidates, timeout, recency fallback—never block the edge.
- Cursors over offsets — Moving rank means honest dup/skip, not fake strong consistency.
Tell it in the room: “Home feed: durable post, async idempotent fan-out to shards where policy allows, read path loads capped candidate IDs, multi-gets bodies, filters blocks, ranks with a timeout, returns a cursor. Celebrity: no O(followers) write—merge on read. When fan-out lags, users still scroll stale mailboxes; when ranker lags, fall back to recency.”
Reference diagram
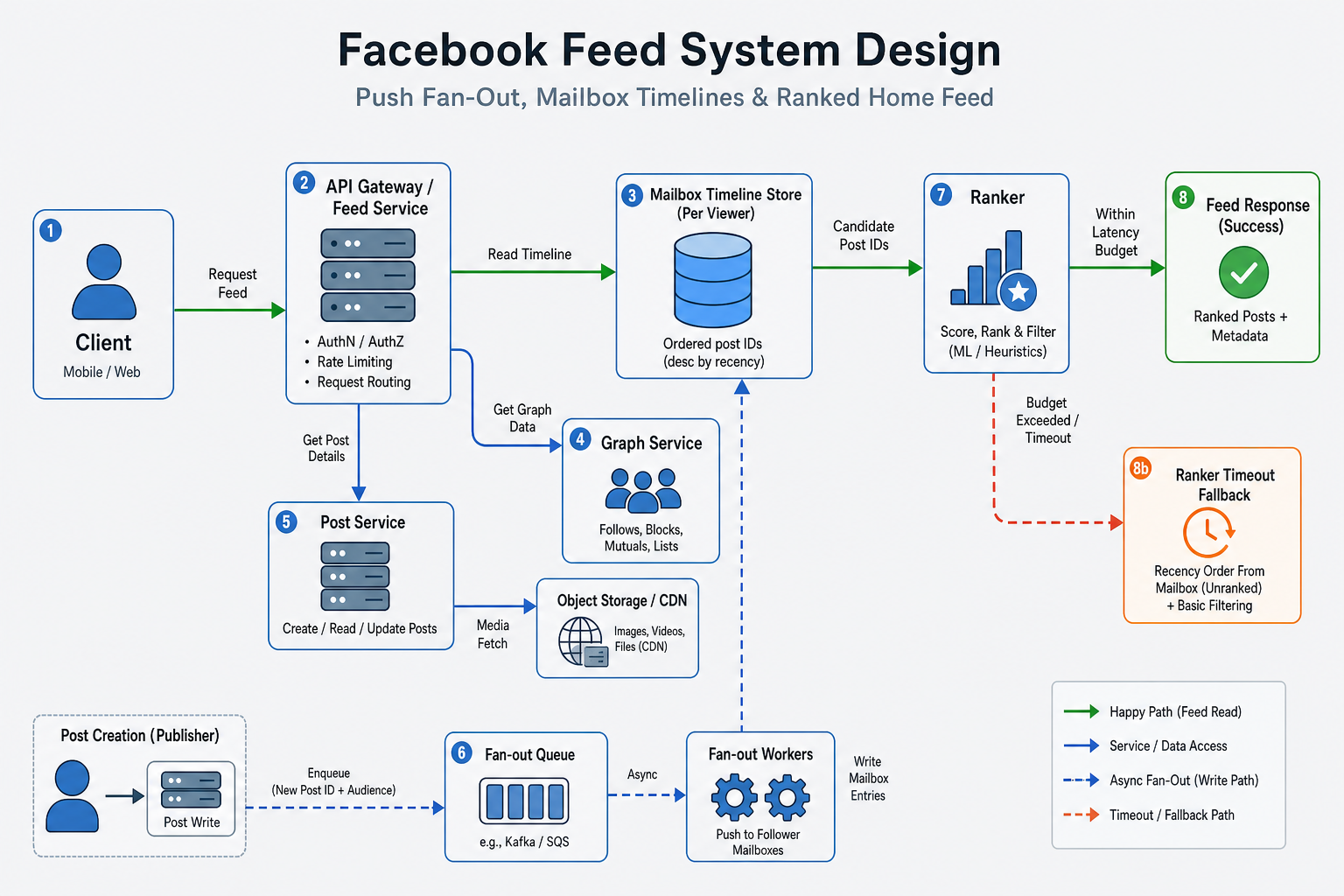
What interviewers expect
Async fan-out; merge+rank on read; celebrity pull merge; timeout fallback to recency.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Fan-out write vs read?
- 50M followers?
- Ranking stale?
- Pagination dupes?
- Queue lag?
Deep-dive questions and strong answer outlines
Normal user posts?
Persist post; async fan-out to follower mailboxes; idempotent workers.
Celebrity?
Skip O(followers) writes; merge on read; partial fan-out to actives only.
Read home feed?
Fetch mailbox ids; batch get posts; rank; cursor by (score,id).
Ranker slow?
Circuit break; recency fallback; bound candidate count.
Unfollow?
Filter at read; async purge stale mailbox entries.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: ML ranking depth?
A: Interface + freshness SLA enough.
Q: Only fan-out?
A: Universal fan-out fails celebrities.
Q: Strong consistency?
A: Eventual seconds lag OK; safety blocks stricter.
Q: vs Twitter?
A: Emphasis on ranking + multi-content types.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.