System design interview guide
Instagram Feed System Design
Reels and photos share one home feed but media bytes dwarf text metadata—ranking must not block on transcoding, and a influencer post cannot fan out 50M mailbox writes. Media pipeline + hybrid feed is the Instagram-shaped interview.
Problem statement
Instagram-class feed with media pipeline, hybrid fan-out, explore.
Introduction
You post a Reel on spotty LTE. The app says “posted” in two seconds—but playback stutters because only a poster frame exists while the full bitrate ladder is still encoding. Your friend’s feed still shows yesterday’s order because fan-out is backed up. Same product, three different clocks: upload ack, media ready, timeline visible.
“Design Instagram’s feed” means: scroll a stream from people you follow, upload photos/video that become visible worldwide, and deliver bytes on mobile without unbounded work per swipe or full-resolution video on every load.
Most interviews focus on Home (often Stories); Explore is optional unless they widen scope.
Interviewers grade two layers:
- Light metadata — who posted what, order, permissions, candidate post IDs.
- Heavy media — object storage, transcoding, CDN URLs, adaptive playback.
The feed is not one SQL join. It is pointers, async pipelines (fan-out, transcode, notifications via queues or Kafka with idempotent workers and outbox/CDC), and skew: many scroll, few post, a few creators are broadcasters.
Weak answers ship full video in the feed JSON. Strong answers cap candidates, bound ranker time, and say what the UI shows when transcode or CDN lags.
If you remember one thing: Metadata path fast; bytes path async—never block post ack on every encoding ladder.
How to approach
Start by clarifying scope—not by drawing every box. Agree whether you mean Home vs Stories vs Explore, whether ranking is part of the story, and how fresh content must be: seconds for “can I see this post?” vs minutes for “every quality tier of the video exists.” That choice steers you toward time-ordered feeds vs heavier online ranking.
Next, do one rough capacity pass: feed reads vs new posts, fan-out (how many followers get a copy of a post ID) for a normal user vs a mega-creator, and bandwidth out (egress) as a real cost—not only “requests per second.” Then walk through one upload (upload → storage → post record → background jobs) and one feed read (candidate IDs → fetch text metadata → turn file hints into CDN URLs → optional rank → cursor). Debate Redis vs Cassandra only after that story is clear.
If time is tight, prioritize video and hot accounts: how you treat celebrities, what happens when encoding queues grow, and how pagination behaves when order can change. That beats adding another unnamed rectangle to the diagram.
In the room: “I’ll split metadata and media, walk one Reel upload and one feed page, then hybrid fan-out and degradation.”
If you remember one thing: Story before store brands.
Interview tips
Six exchanges common on Instagram-style feed questions.
Post ack vs video ready
You: “We wait until transcoding finishes before returning success.”
They ask: “User on 3G posts a 60s Reel—what happens to post latency?”
Land here: Return success when metadata + blob upload are durable; media_processing: pending in API; client shows poster frame and ABR while ladders land async. Blocking HTTP on ffmpeg is a scale mistake.
Fan-out to everyone
You: “Every post fans out to all followers immediately.”
They ask: “Creator with 30M followers—how many mailbox writes?”
Land here: Hybrid: push for long tail; merge on read or author-indexed tail for head; partial fan-out to active users only. Name queue depth and storage blast radius.
Feed as one join
You: “SELECT posts JOIN follows ORDER BY time.”
They ask: “Someone follows 5,000 accounts—cost per swipe?”
Land here: Candidate IDs from mailboxes + optional merge; multi-get post rows; no giant join on hot path. Cap candidates before rank.
CDN as a label
You: “We use a CDN.”
They ask: “Viral Reel—what object key melts, and what do you purge?”
Land here: Variants per resolution/ladder; signed URLs; origin shield; hot key on one object id—monitor egress and origin CPU, not only API QPS.
Ranking on the critical path
You: “Home For You runs the full model synchronously.”
They ask: “Feature store slow—does scroll stop?”
Land here: Bounded candidates → rank with hard timeout → recency fallback. Separate candidate generation from scoring.
Stories bolted on
You: “Stories are just posts with a flag.”
They ask: “What happens at 24 hours?”
Land here: TTL, sweepers, often separate storage/API; different ranking hooks; server-authoritative expiry—not only client hide.
If you remember one thing: Name variant URLs, hybrid fan-out, and processing state in the API—not “we cache the feed.”
Capacity estimation
Use these only as ballpark anchors—adjust with your interviewer:
| Input | Order of magnitude |
|---|---|
| DAU | 100M+ (varies by region) |
| Feed fetches per DAU | Many sessions; clients reuse data, so not every scroll hits the server like a full reload |
| Uploads / day | Tens of millions; video drives most storage and processing cost |
| Read vs write QPS | Far more feed reads than new posts |
| Egress | Often the main cost alongside compute—say data out, not only request counts |
Implications:
Any design where work per post grows with follower count without a cap breaks for celebrities. Transcoding and fan-out should run asynchronously with backpressure when queues grow. The feed request should limit how many candidates enter ranking so tail latency (for example p95) stays under control.
If you remember one thing: Egress and encoding are first-class costs—not footnotes after QPS.
High-level architecture
How to use this section in an interview.
Your goal is one coherent system picture: which services exist, what each one stores, and how a read differs from a write. The architecture is split on purpose: thin orchestration and metadata (fast, per-scroll) stay in the feed path; large files live in object storage and are served from the CDN; slow work (transcode, fan-out to many followers) runs asynchronously so posting and scrolling stay responsive. The subsections below give you the explanation first, then a step-by-step script you can narrate while you draw.
What the architecture is (explain before you label boxes)
From the phone’s perspective, opening or scrolling home means: “give me the next batch of posts after where I left off.” The app receives JSON—captions, author fields, and URLs for thumbnails and video—not multi-megabyte files inlined in the response. The device then fetches media separately from CDN caches close to the user.
From the backend’s perspective, there are two main flows on the same diagram:
-
Read path (scroll): Edge / API authenticates and rate-limits → Feed service asks for the next page (using a cursor) → it loads candidate post IDs from mailbox / merge / hybrid storage → it batch-loads post rows and author info from a post-oriented store → it checks graph rules (blocks, privacy) → it turns media keys into CDN URLs → an optional ranker reorders within a time limit → the API returns items + cursor. Bytes do not stream through the feed tier on this path—only pointers and URLs do.
-
Write path (post + fan-out): Upload lands in object storage; a post record becomes durable with processing flags; transcode / thumbnail jobs run in the media pipeline; when the product allows visibility, fan-out workers enqueue or write post IDs into per-viewer candidate lists (mailboxes) where your push policy applies, or you rely on merge for hot creators. That split—durable metadata first, async encoding and distribution—is the core architectural idea.
Why so many boxes?
Separation of concerns: the feed service is an orchestrator, not the long-term source of truth for every post or every friendship. Candidate storage answers “in what order might posts appear for this viewer?” Post service answers “what is this post?” Graph service answers “who is this viewer allowed to see?” Object storage + CDN answer “where are the bits?” Keeping those questions in different layers is how you bound work per scroll and scale media independently from feed logic.
Read path (narrate in this order while you draw)
- Edge + API — TLS, session auth, rate limits; abuse and routing before feed logic.
- Feed service — “Next page” for this viewer + cursor; enforces a cap on candidates and downstream calls (work budget).
- Candidate IDs — Ordered list from mailbox (prepared on publish), merge (combine at read time), or hybrid; cheap before heavy joins.
- Batch metadata — Multi-get posts and authors (captions, timestamps, avatars, media keys)—still text-sized.
- Graph filters — Blocks, private accounts, mutes; read-time checks when safety must win over stale lists.
- Media → CDN URLs — Map storage keys / ladder state to HTTPS URLs for the right variant (thumb, manifest, etc.).
- Rank (optional) — Ranker with hard timeout and fallback ordering if it misses budget.
- Response — Feed items + opaque cursor for the next request.
Interview line to remember:
The hot path is IDs → metadata → policy → link strings; pixels ride the CDN.
Who owns what (typical split)
Use this as a legend for your diagram—each bullet is one role, not one mandatory microservice name.
- API / BFF — Auth, routing, timeouts; may batch downstream calls so the mobile client is not chatty.
- Feed service — Read-path orchestration: candidates, graph checks, metadata hydration, URL assembly, rank budget, cursor. Caps work here.
- Mailbox / timeline store — Per-viewer ordered post IDs (or score+id)—not full post JSON at rest.
- Post service — Source of truth for captions, author id, timestamps, privacy, media keys, processing state.
- Media pipeline — Transcoders, thumbnails, ABR ladders; triggered by queues or streams after upload.
- Object storage + CDN — Blobs and segments; regional edge caching; signed or stable paths.
- Graph service — Follows, blocks, mutes; usually heavily cached; feed asks “may this viewer see this author?”
- Fan-out workers — Take
(post_id, author_id)and append to follower mailboxes where push applies; idempotent writes. - Ranker — Scores or reorders candidates; treat as latency-SLA’d with timeout + fallback.
Caching (say it explicitly): Cache post metadata, profiles, following sets, and CDN edges; be honest that some fields can be briefly stale (display name) while safety paths (blocks) are re-checked when serving.
Celebrity / hybrid (point at the diagram): If you only draw push fan-out, expect a follow-up on mega-creators. Show merge from an author-indexed recent tail (or partial fan-out) into the candidate pool—policy, not magic.
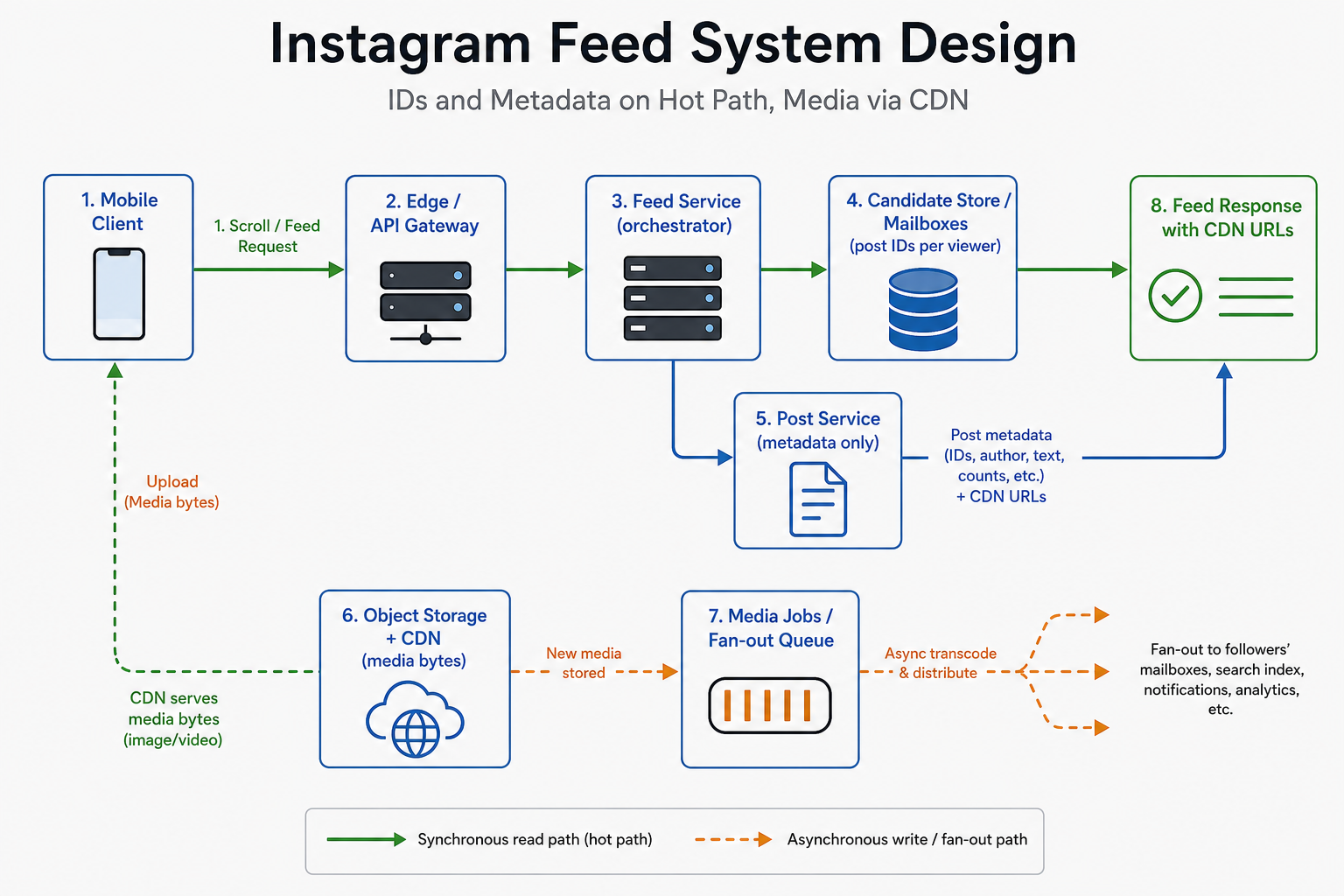
Reference diagram (one picture)
Read path flows left to right across the top; upload + fan-out sit on the write path below. Post svc connects to media jobs and object store because metadata points at blobs; CDN is where clients actually download media.
[ Mobile client ]
→ [ Edge / API ] → [ Feed svc ] → [ Candidate store: mailboxes + optional merge ]
│ │ │
│ │ └──→ [ Ranker ] (timeout + fallback)
│ │
│ ├──→ [ Graph svc ] (follows, blocks)
│ │
│ └──→ [ Post svc ] → metadata only
│ │
│ ├──→ [ Media jobs ] → transcode / thumbs
│ │
│ └──→ [ Object store ] → [ CDN ] → (video/image bytes)
│
└── upload: [ Upload API ] → object store → enqueue transcode → post row READY
fan-out: [ Queue ] → workers → viewer mailboxes (idempotent)
In the room:
Explain the split (orchestration vs blobs vs async work) in about a minute. Walk the read path with concrete numbers: latency budget, max candidates, ranker timeout, CDN URL shape.
Then add the write path: durable post, async transcode, async fan-out, idempotent mailbox writes. Instagram-specific detail: the HTTP ack for posting should not wait for every encoding ladder—metadata and upload durability come first.
If you remember one thing: Hot path is IDs → metadata → policy → CDN URLs; pixels never stream through the feed tier.
Event- and message-driven architecture (async half of the HLD)
The request/response diagram is only half the story. Transcoding, fan-out, notifications, search indexing, and analytics are too slow and too bursty to run inline in the post HTTP handler. Production-shaped designs decouple with queues or event streams so work can scale, retry, and back off independently of the API.
Why messages or events?
| Pattern | What you get | What you trade |
|---|---|---|
| Task queues (SQS, RabbitMQ, Redis Streams as a queue, etc.) | Explicit jobs: “transcode post_id,” “fan-out batch for shard X”—easy retry, visibility timeout, dead-letter queues | Ordering and replay semantics vary by product; fan-out may need many messages or batch workers |
| Log-based events (Kafka, Pulsar, Kinesis) | Durable ordered stream of facts (PostCreated, MediaReady); many consumers (fan-out, search, metrics) without coupling the writer | Operational complexity; consumers must be idempotent; schema evolution needs discipline |
| Hybrid | Critical path job queue + Kafka for fan-out and downstream systems | Two systems to run and monitor |
Typical “facts” you might emit (names illustrative): PostCreated / MediaUploadComplete, TranscodeComplete (per variant or ladder), PostVisibleToFollowers, FanOutRequested, StoryExpiringSoon. Consumers include transcoders, mailbox writers, push notification senders, and search indexers—each subscribes to what it needs.
Delivery guarantees (say this in the interview): Most managed queues give at-least-once. Workers must be idempotent (post_id + viewer_shard dedupe, unique keys in DB). Exactly-once end-to-end is rare; dedupe at the sink is the practical pattern.
Reliable handoff from the database to the bus: After a transaction commits a post row, you still need a message to enqueue work. Common patterns: transactional outbox (same DB transaction writes an outbox row; a publisher process reads and pushes to Kafka/SQS), or DB CDC (change data capture) into a stream. Avoid “commit then best-effort send to queue” without a plan for lost messages on process crash.
Small diagram (add to the whiteboard below the sync path):
[ Post API ] → (txn) → [ Posts DB ] + [ Outbox row ]
↓
[ Outbox publisher / CDC ]
↓
[ Queue or Kafka: PostCreated, TranscodeJob, ... ]
↓
┌────────────────────┼────────────────────┐
▼ ▼ ▼
[ Transcode workers ] [ Fan-out workers ] [ Notifications ]
Other high-level design patterns that fit this problem
You do not need every buzzword—pick one or two that match the story you drew.
- CQRS-style separation (lightweight): Writes go to the authoritative post store; reads for the feed use precomputed candidate lists and cached metadata—different shapes optimized for different access paths. Full CQRS with event sourcing everywhere is overkill for most interview answers; separate read models for feed IDs vs write model for posts is enough.
- Choreography vs orchestration: Choreography — services react to events (transcode finishes → emits → fan-out starts). Orchestration — one workflow engine coordinates steps. Feeds often look choreographed in the small; orchestration appears when you need strict ordering and compensation (rare on the hot path).
- API Gateway / BFF: Edge handles auth, rate limits, routing—already in your diagram; BFF aggregates feed + profile fragments for mobile.
- Anti-corruption / bounded contexts: Post domain vs Feed domain vs Graph—different teams and release cadences; events are the contract between them.
- Strangler fig (when migrating): If you replace a legacy feed store, dual-write or shadow read with feature flags—migrate traffic gradually.
Interview line: The sync path is small and bounded; the async path is message-driven, idempotent, and observable (queue depth, consumer lag, DLQ age).
Core design approaches
Most of the interview is not picking a brand of database—it is walking forks where each choice trades latency, cost, complexity, and failure behavior. The sections below are the usual decision surfaces: how uploads relate to encoding, how feed IDs are produced, how Stories differ from feed posts, and how ranking sits on top without blowing the p95 budget.
Upload and media processing
Baseline pattern. Clients upload chunks to object storage; the API creates a durable post row with media_processing: pending (or similar). Transcoders build ABR ladders, thumbnails, and poster frames; the row moves to ready or partial states as artifacts land. The phone may show optimistic UI; server truth stays metadata + pointers, not “every pixel is final.”
Tradeoffs to articulate:
| Decision | If you optimize for… | You usually accept… |
|---|---|---|
| Resumable / chunked upload | Flaky mobile networks and large videos | More moving parts (session IDs, part completion, cleanup of abandoned uploads) |
| HTTP success when… | Fast “posted” feeling | Processing states in the API—clients must render pending / partial / failed honestly |
| …metadata + blob durable vs …every ladder exists | Low post latency and stable APIs | Users may play before all bitrates exist; client uses ABR and lower rungs first |
| Many ladder rungs + renditions | Playback quality and smooth ABR | Storage, transcode CPU, and cache cardinality (more URLs to purge and warm) |
| Fan-out / visibility in the upload request | Immediate visibility in followers’ lists | Spiky load and tighter coupling to posting—most designs enqueue fan-out after the row is durable |
| Synchronous transcode on critical path | Simpler mental model for “ready” | Terrible tail latency and fragile post ACK—strong interviewers treat this as a mistake at scale |
Interview line: Separate “can we show something?” (poster frame, low rung) from “is the full product-quality ladder done?”—and put only the first class of work anywhere near the user-visible ACK if you can avoid it.
Feed assembly (push / pull / hybrid)
The core tension is where you pay cost: on publish (writes to many mailboxes) or on read (merge many authors into one timeline).
Push (fan-out on write). When someone posts, workers append post IDs to each follower’s mailbox (possibly sharded). Pros: Feed reads are simple and fast—slice a precomputed list, then hydrate. Cons: Write amplification scales with followers; a celebrity post can mean millions of writes or queue depth unless you cap, sample, or refuse naive full fan-out. Staleness in mailboxes is real; teams often filter at read (blocks, deletes) even when IDs were pushed earlier.
Pull (merge on read). At scroll time, fetch recent post IDs from each followed account (or from author-indexed tails) and merge by time or score. Pros: No per-follower write for mega-creators—publish cost stays O(1) with respect to audience size at post time. Cons: Read path gets heavier as fan-in grows (many follows → big merge); hot authors and cache misses show up as p99 pain; you need indexes, limits, and caching of author tails.
Hybrid (what production-shaped answers describe). Push for the long tail; merge or partial fan-out for the head (celebrities). Pros: Balances read latency and write blast radius. Cons: Two code paths and a policy layer (who counts as “big,” how to dedupe when both paths contribute IDs). The tradeoff is operational complexity vs impossible pure-push or pure-pull at both extremes.
Cross-cutting tradeoffs (say them out loud):
- Mailbox size / retention: Unlimited per-user lists simplify reads until storage and compaction hurt; trimming and pagination semantics must stay consistent with cursors.
- Ordering: Strict time order across all sources is easy to explain; algorithmic order usually needs candidate generation separate from final sort (see Ranking)—mixing the two without naming budgets fails follow-ups.
Stories
Stories share DNA with feed posts (same graph, often same media pipeline) but differ in product rules—most notably short lifetime.
Tradeoffs:
| Topic | Typical choice | Tradeoff |
|---|---|---|
| Lifetime | Fixed TTL (e.g. 24h) | Clock skew and “what counts as viewed” are edge cases; sweepers vs lazy delete change ops load |
| Storage model | Separate Story rows / buckets vs same posts table with type=story | Separate keeps queries and TTL jobs simpler; unified reduces duplication but risks wrong retention or ranking if you forget flags |
| Cleanup | Batch sweeper + TTL indexes | Missed sweeper runs or backlog → orphaned blobs unless object lifecycle matches metadata TTL |
| Ranking / surfacing | Often different rules than main feed (close friends, reactions) | Reusing the same ranker without inputs for ephemeral context produces wrong ordering—say different features or caps, not only “another feed” |
| Seen / replay state | High write volume if you persist every view | Sampling, batching, or eventual sync vs perfect per-tile state—cost vs fidelity |
Interview line: Stories are not “feed with a flag”—they are time-bounded inventory with expiry semantics and usually different notification and ranking expectations.
Ranking
Treat ranking as a contract, not a magic box: candidates in (bounded list of IDs), ordered list out, under latency and safety constraints.
Structural tradeoff: candidate generation vs scoring. Generating candidates (who might appear) is often cheaper and more stable than scoring every post in the world. Scoring can use heavy models and features. If you conflate the two, every feed fetch becomes “run the full recommender on everything”—p95 dies. Strong answers cap candidates, then rank.
Quality vs latency. Deeper models and more online features improve engagement; they also add dependencies and tail latency. The usual mitigation is strict timeouts, fallback to recency or a lighter model, and caching of scores or partial results where product allows.
Product modes (e.g. Following vs algorithmic Home). You do not need two databases for credibility—you need a clear story: different candidate sources (only follows vs follows + exploration), different weights, or different freshness SLAs. Chronological surfaces may skip heavy ranking entirely; Home might blend sources—name caps and timeouts either way.
Pagination under changing rank. If order moves between requests, offset pagination lies; cursors tied to (score, id) or opaque tokens are standard, with honest dup/skip behavior. Trading perfect stability for simplicity is a valid product discussion—pretending strong consistency without cost is not.
Interview line: Say what happens at the ranker budget (e.g. 300ms)—timeout, fallback order, and whether the client refetches—before you argue TensorFlow vs PyTorch.
Detailed design
Write path (post + media)
- Client obtains upload URLs or streams chunks to storage.
- Post API creates row: author, caption, media keys, timestamps, visibility,
processingflags. - Enqueue transcode/thumbnail jobs; do not block HTTP until all ladders exist.
- Fan-out or enqueue fan-out when the post is visible per product rules (sometimes after basic processing).
- Idempotent workers write
(viewer_shard, post_id)with dedupe keys.
Side effects—search index, notifications, Story fan-out—trail the critical path.
Read path (home feed)
- Resolve viewer and session context (experiments, mode).
- Load candidate IDs (mailbox slice + merge + optional exploration—if in scope).
- Batch fetch post metadata and authors; filter blocks and policy.
- Resolve media: pick variant (thumb, preview, HLS manifest URL) per client capability.
- Rank within budget; trim to page size; emit cursor.
If you only say “we call ranking,” say what happens at 300ms: timeout, cache last good order, or a recency slice.
Data schema, storage, and caching (Redis, DBs, blobs)
At scale there is no single database that wins every access pattern. You separate transactional metadata (posts, users), graph edges (follows, blocks), high-volume read lists (per-viewer candidate IDs), blobs (object storage), and ephemeral / hot data (caches, Redis). The interview goal is to name the pattern and why—not memorize one vendor.
What lives where (logical split)
| Kind of data | Typical home | Why |
|---|---|---|
| Post & user records | Relational DB (PostgreSQL, MySQL, or sharded SQL) or document store | ACID-ish create/update for posts; indexes on author_id, created_at; constraints and migrations teams know how to operate |
| Per-viewer feed candidates (ordered post IDs) | Wide-column (Cassandra, Scylla), key-value with range reads, or Redis structures (see below)—often sharded by viewer_id | Huge cardinality (one row/stream per user); append on fan-out; range scan for “next page” |
| Social graph (follows, blocks) | Graph DB or edges table + heavy cache | Adjacency queries (“who does X follow?”); blocks must be correct—often read-time checks with cached sets |
| Media blobs | Object storage (S3, GCS, R2, MinIO) | Bytes don’t belong in OLTP rows; lifecycle rules for TTL Story objects |
| Hot read path | Redis (or Memcached), CDN for URLs | Sub-ms reads for repeated keys; no strong durability requirement for cache |
| Async work | Queues (Kafka, SQS, RabbitMQ, etc.) | Fan-out, transcode jobs, notifications—backpressure and replay |
Example schemas (illustrative—not one true DDL)
Posts (relational or document collection)—source of truth for metadata and pointers to media:
post_id(PK),author_id,caption,visibility,created_at,updated_atmedia_processing(pending|partial|ready|failed)media_manifest— JSON or columns: original object key, ladder entries (key per variant, width, codec, bitrate), poster key, thumbnail key
Users / profiles:
user_id(PK),username,display_name,avatar_urloravatar_object_key,is_private, …
Graph edges (many designs use follows + blocks tables):
follower_id,followee_id,created_at— composite PK or unique index; shard byfollower_idorfollowee_iddepending on query patternblocker_id,blocked_id,created_at
Mailbox / timeline (per viewer)—store IDs, not full posts:
- Key:
viewer_id+ shard; ordered list:post_id, optionalinserted_ator score for ranking - Compaction / trim old tail for storage; cursor must align with how you slice this structure
Stories (often separate table or type + TTL column):
- Same media pointers as posts plus
expires_at,story_kind,seenstate (or separate seen store if write volume is high)
Sessions / devices (optional dedicated table or auth provider):
user_id,device_id,refresh_tokenhash,expires_at
Object storage layout
- Prefix by
post_idorauthor_id/post_idso lifecycle and permission deletes can bulk-prefix delete when needed. - Originals vs derived (thumbnails, ladder segments): separate keys or folders so transcode failures can retry per artifact.
- CDN URLs either embed the key path or use signed URLs with short TTL; purge / invalidate on bad encode or takedown.
Redis: what it is good for (and what to avoid)
Redis is often fast RAM with TTL—not a replacement for durable post storage unless you are very explicit about sync and durability (Redis persistence, AOF, or write-through to DB).
Strong fits:
- Cache-aside for hot post metadata (
GET post:{id}), author profiles, follow counts (with eventual consistency and invalidation on update) - Rate limiting and abuse tokens (sliding window counters per IP / user)
- Short-lived session or feature flags for feed experiments (paired with a stable cursor contract)
- Sorted sets or lists for small per-user tail caches (e.g. “last N post IDs for merge”)—bounded size, TTL, not the only copy of a 10M-follower mailbox
- Distributed locks or coordination for fan-out idempotency keys (careful: TTL locks, fencing)
Risky or “say it carefully” fits:
- Entire mailbox for every user in Redis only — memory cost explodes; recovery after failover is hard; production systems often use Cassandra/wide-column or tiered storage for mailboxes, with Redis as cache layer on top
- Primary store for fan-out without durability story — interviewers may push on what happens when Redis dies
Memcached vs Redis: Memcached is pure cache (simpler); Redis adds structures (sets, sorted sets, streams) and TTL—useful when you need rate limit + small structured state in one place.
Cassandra / wide-column (when interviewers mention it)
Good for: time-ordered wide rows—(viewer_id, bucket) → clustering columns (post_id, ts) or score; high write fan-out from fan-out workers; tunable consistency. Tradeoff: query model is rigid (design for access path first); operational learning curve.
Putting it together in one sentence
Postgres (or similar) holds authoritative posts and users; mailbox/feed storage holds IDs per viewer at scale; object storage holds media; Redis caches hot reads and powers rate limits and small ephemeral structures; queues move async work. Draw the arrows and say what is source of truth vs cache vs derived.
If you remember one thing: Name source of truth vs cache vs derived for each arrow—not “we use Postgres and Redis.”
Key challenges
- Egress and encoding cost: Video dominates bandwidth and CPU in the pipeline; ABR and CDN are not optional decorations.
- Skew: One creator, huge follower count—naive fan-out is storage and queue blast radius; naive pull is read-time merge cost.
- Pagination vs ranking: Order moves between requests; cursors and occasional dup/skip are normal—don’t promise offset consistency at scale.
- Stories vs feed: Different retention, TTL jobs, and product rules; conflating them creates buggy cleanup and ranking.
- Seen / replay: Updating every story view synchronously can write-storm; batching, sampling, or eventual sync is often the reality.
- Transcode lag: Users still expect a feed; processing states and lower rungs must be first-class in the API contract.
If you remember one thing: Video + skew dominate cost—fan-out and egress are not afterthoughts.
Scaling the system
Shard mailboxes by viewer; shard post metadata by post id or author-time; CDN is how you scale bytes. For hot posts, use request coalescing (singleflight) and TTL jitter on metadata caches—thundering herd on a viral Reel ID is a classic failure mode.
Multi-region: graph and media replication lag is real; eventual visibility across regions is more honest than strong global consistency for every mailbox row.
If you remember one thing: CDN scales bytes; mailboxes scale read QPS—hot post IDs need singleflight.
Bottlenecks and tradeoffs
Encoding cost vs playback quality
The tension — More ABR ladders and prefetch feel great on Wi‑Fi; each variant is storage + transcode CPU.
What breaks — Transcode queue backlog; users see processing forever during incidents.
What teams do — Priority lanes; serve low rungs first; shed non-critical encodes; honest media_processing states in API.
Say in the interview — Separate “can show something” from “full ladder done.”
Push fan-out vs read merge
The tension — Push makes scroll cheap; celebrities make writes impossible.
What breaks — Queue depth and storage blast radius on one post.
What teams do — Hybrid policy by follower count; merge author tail on read; cap candidates.
Say in the interview — Name who you fan out to—not “Kafka.”
Consistency vs mobile latency
The tension — Strong global consistency is slow; feeds tolerate eventual visibility.
What breaks — “I see it, you don’t” across regions; dup/skip on pagination when rank moves.
What teams do — Read-time block filter; opaque cursors; regional SLAs for visibility.
Say in the interview — Admit eventual mailboxes; never fake one global sync lock.
If you remember one thing: Instagram tradeoffs are bytes + skew—not only feed algorithm labels.
Failure handling
- Ranker slow or down: Timeout; fall back to recency or last cached ranked slice; feature flags to disable heavy models.
- Transcode backlog: Show processing or lower bitrate; do not fail the whole feed; alert on queue age and oldest pending job.
- CDN / origin hot spot: Origin shield, request coalescing, regional failover; monitor origin load separately from API QPS.
- Fan-out backlog: Reads still succeed from stale mailboxes + merge; visibility latency grows—product messaging beats silent failure.
- Graph service degraded: Circuit break; for safety paths, fail closed where abuse risk is high; otherwise bounded retries.
If you remember one thing: Never return an empty feed when transcode lags—return posts with processing media states.
API design
Illustrative REST surface (GraphQL is fine if you discuss batching and N+1—feeds amplify bad graphs).
POST /v1/media/uploads # or /uploads:init + chunked parts
POST /v1/posts
GET /v1/feed
GET /v1/posts/{post_id}
GET /v1/stories/reel # or nested under users
POST /v1/users/{user_id}/follow
DELETE /v1/users/{user_id}/follow
POST /v1/posts/{post_id}/like # async side effects OK
GET /v1/posts/{post_id}/comments
Home feed — GET /v1/feed
| Query param | Role |
|---|---|
cursor | Opaque continuation; may embed ranker state |
limit | Page size (cap server-side, e.g. ≤ 20–50) |
mode | e.g. following vs for_you if product has both |
session_id | Experiments / snapshot behavior (optional) |
Response sketch: { "items": [ Post ], "next_cursor": "...", "has_more": true }. Each Post includes media with status (ready/processing), urls or playback descriptors per variant, counts, author summary.
Errors: 401 / 429 with Retry-After; avoid leaking blocked user existence if policy requires.
Upload — POST /v1/media/uploads (pattern)
- Return upload session id and part URLs or signed PUT targets.
- Idempotency-Key on POST /v1/posts so flaky networks don’t duplicate posts.
Stories — read
Often separate resource with TTL hints in response; client hides expired client-side but server is source of truth for ordering and privacy.
Cross-cutting
- Rate limits on upload and create to fight abuse.
- Version mobile clients; backward-compatible field adds for media states.
In the room:
One minute on idempotent post create, cursor semantics for GET /v1/feed, and why likes don’t own feed p95—that’s enough to sound like you shipped the APIs.
Production angles
Green transcode dashboards do not mean smooth Reels. Users care about playback, feed freshness, and Stories that expire on time—not box count.
Transcode backlog while posts “succeed”
What users saw — Post shows “shared”; Reel spins on processing; quality stays low for hours after an incident.
Why — Transcode capacity is finite; metadata and fan-out can run while ladders lag.
What good teams do — Alert oldest job age; priority lanes; serve low rungs first; feature flag to relax quality temporarily.
Ranker regression or slow feature store
What users saw — Feed spinners; unrelated routes slow when ranking deploy regresses.
Why — Ranker on hot path without timeout wedges gateway threads.
What good teams do — Hard timeout, circuit breaker, recency fallback; separate SLOs for feed load vs perfect rank.
CDN / origin meltdown on one object
What users saw — One viral Reel stutters globally; origin errors while edge hit ratio looks fine.
Why — Every feed item references the same object key; aligned cache miss → thundering herd on origin.
What good teams do — Singleflight; origin shield; prewarm launches; watch egress and origin CPU per key.
Stories expiry and “ghost” content
What users saw — Expired Stories still visible, or new ones missing, after sweeper lag or stale CDN.
Why — TTL spans metadata, blobs, CDN, and client cache—clock skew and regional lag add fuzz.
What good teams do — Server authoritative expiry in API; short manifest TTL; sweeper metrics on orphans.
How to use this in an interview — One story: transcode queue age, ranker timeout, or CDN stampede. One metric, one mitigation, honest UX (processing state, lower bitrate)—not a blank feed.
What should stick
You do not need every datastore name. You should leave knowing:
- Two layers — Fast metadata path; heavy media async (upload → transcode → CDN).
- Hybrid fan-out — Push where cheap; merge for mega-creators; bounded candidates before rank.
- Post ack ≠ all bitrates —
media_processingstates; ABR and poster frames first. - Hot path = IDs → URLs — Bytes ride CDN; feed JSON stays small.
- Degrade honestly — Ranker timeout, transcode backlog, CDN miss—placeholders beat blank screens.
Tell it in the room: “Upload to object storage, durable post row, async transcode and idempotent fan-out to mailboxes where policy allows. Read: capped candidate IDs, multi-get metadata, CDN URLs per variant, rank with timeout, cursor. Celebrity: merge on read. When transcode lags, show processing; when ranker lags, recency fallback; Stories need TTL and sweepers—not a flag on the feed table.”
Reference diagram
What interviewers expect
Async media pipeline; hybrid feed; shard counters; separate explore retrieval.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Photo upload path?
- Feed vs explore?
- Celebrity fan-out?
- Stories storage?
- Like scale?
Deep-dive questions and strong answer outlines
Post photo?
Presigned upload → object store → async transcode → post metadata with CDN URLs → fan-out job.
Following feed?
Hybrid mailbox merge; rank with cached scores; paginate cursor.
Explore?
Offline candidates + online rerank; not same as following fan-out.
Stories?
TTL store 24h; sequential manifest; fan-out to followers only.
Viral likes?
Counter shard per post_id; rate limit writes; cache read counts.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Filters GPU?
A: Client or async—off critical path.
Q: DMs?
A: Separate stack unless scoped.
Q: Reels delivery?
A: CDN + adaptive streaming like video products.
Q: vs Facebook feed?
A: Heavier media constraints on upload/read.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.