System design interview guide
Job Scheduler System Design
Midnight cron fires 50K jobs at once and your cluster oversubscribes CPUs while a payment reconciliation job waits behind a low-priority email batch. Scheduling, priority, retries, and exactly-once side effects define the interview.
Problem statement
Distributed job scheduler: cron, priorities, retries, worker leases.
Introduction
Midnight UTC hits. A million cron jobs wake at once. Billing runs. Then billing runs again—because the scheduler leader failed over and the new leader did not know the first batch already fired. Support finds duplicate charges. Marketing emails went out ten times.
That is what users feel when “run at T” is treated like a single-server cron tab.
Interviewers care about three failures: duplicate execution, lost jobs, and stuck jobs after a worker dies halfway. The product wants billing once and emails once—not a lecture on TCP.
Your design should center a state machine, leases, and idempotency. Weak answers draw cron on one VM. Strong answers separate when (time index + leader or shard) from who runs (workers + claim).
If you remember one thing: Scheduling is durable timers at scale—separate “fire at T” from “execute safely.”
How to approach
Talk like you are walking one job from “scheduled” to “done”—not listing queue brands.
Define execution guarantee first: almost always at-least-once on the wire, effectively-once for business side effects via idempotency keys or external dedupe. Then sketch tables (jobs, executions, optional deps). Walk one due job → claim → run → ack or retry. Only then cron and DAG depth.
In the room: “I’ll pick at-least-once delivery with idempotent handlers, then walk one job through claim and lease before cron and dependencies.”
If you remember one thing: Guarantee delivery attempts separately from business effects once.
Interview tips
Five exchanges that show whether you have operated a scheduler—not just drawn one.
At-least-once vs exactly-once
You: “We guarantee exactly-once execution.”
They ask: “Worker crashes after your callback returned 200 but before ack—what happens?”
Land here: The wire is at-least-once. Exactly-once effects come from idempotent handlers, dedupe tables, or external systems keyed by job_id. Say that out loud.
Visibility timeout and leases
You: “Workers pull from SQS and delete the message when done.”
They ask: “Job takes ten minutes; visibility is thirty seconds—do you lose work or run twice?”
Land here: Use a lease (locked_until, heartbeat extend). When lease expires, another worker may claim—duplicate unless the handler is safe. That is the visibility-timeout pattern.
Cron on leader failover
You: “One cron daemon on a VM.”
They ask: “Leader dies at :00 and the backup starts—does midnight billing fire twice?”
Land here: Single leader tick with dedupe key (cron_id, occurrence_ts) unique, or fencing tokens so stale leaders cannot enqueue. Mention deterministic job id per scheduled minute.
Clock skew
You: “Run when now() on the host passes T.”
They ask: “NTP drift across fifty scheduler nodes—jobs early or late?”
Land here: Trust stored next_run_at in DB time, not each host’s wall clock. Admit schedules are “within N seconds,” not nanosecond perfect.
Backfill after downtime
You: “Catch up everything that was due while we were down.”
They ask: “Six hours offline—millions of jobs due at once?”
Land here: Rate-limit catch-up. Separate priority lanes for new work vs backfill. Spread cron with jitter so :00 is not a coordinated stampede.
If you remember one thing: After each push, name one mechanism—lease, dedupe key, DLQ, jitter—not “we’ll scale workers.”
Capacity estimation
| Load | Implication |
|---|---|
| 100M+ future jobs | Time-indexed queries or partitioned heaps; avoid full table scans each tick |
| 10M executions/day | Worker pool sizing; batch dispatch from ready queue |
| Peak ~500/s | Horizontal workers; scheduler shard by tenant/hash if tick becomes hot |
| History ~TB/year | TTL archive to cold storage; compliance may require longer retention |
Implications: The scheduler tick path must be O(due batch) not O(all jobs). Executions table grows fast—partition by time.
If you remember one thing: Index for next due, not full scans—and plan for execution history growth.
High-level architecture
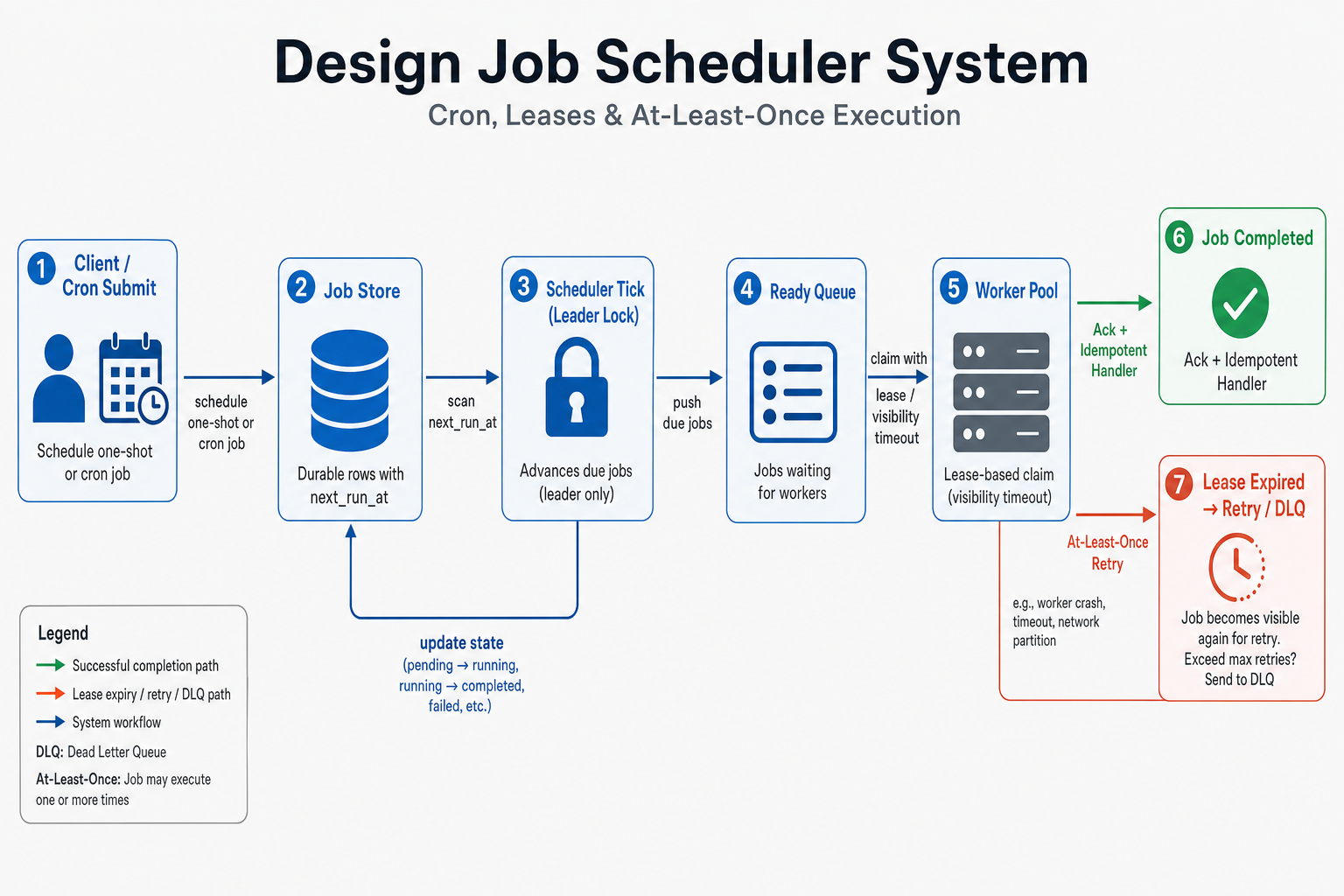
API creates/updates jobs in durable store (SQL or NoSQL with strong writes). Scheduler process(es)—often leader-elected—run a tick loop: query jobs where next_run_at <= now (with index), enqueue to ready queue (Kafka/SQS/Rabbit) or direct claim if DB-based queue. Workers pull or receive push, claim with lease (locked_until, worker_id), execute user payload (HTTP callback, container, script), ack or fail with backoff. History rows append attempt records.
Who owns what:
- Scheduler leader — Advances cron occurrences, hydrates due jobs into ready queue; must not double-insert same occurrence—use unique constraints or dedupe keys.
- Ready queue — Buffers runnable jobs; decouples tick rate from worker CPU; enables backpressure visibility (depth, age).
- Workers — Stateless; horizontal scale; respect lease; extend lease for long jobs (heartbeat).
- Execution store — Audit trail, status, error blobs; may be same DB or analytics sink.
[ Clients / services ]
|
| POST /jobs (sync: persist only)
v
[ Job API ] ──write──► [ Job metadata DB ]
| ^
| | next_run_at index
[ Scheduler Leader ] --------┘
|
| tick: due rows → enqueue (async)
v
[ Ready queue: Kafka / SQS ] ──► [ Worker pool ]
|
| lease + execute
v
[ User workload + DLQ on poison ]
Cron / deps: scheduler expands next occurrence → same pipeline
In the room: Say async boundary clearly: HTTP returns 202 after persist—execution is later. Then describe lease and retry.
If you remember one thing: API persists; scheduler enqueues; workers claim with lease.
Core design approaches
Database-as-queue vs external queue
DB polling with SKIP LOCKED (Postgres) can work at moderate scale—simpler ops, harder to scale tick. External queue adds moving parts but smooths bursts and standardizes retry/DLQ.
Single leader vs sharded schedulers
Single leader tick is easy to reason about; shard by hash(tenant_id) when one leader cannot scan enough rows—each shard owns subset of crons.
Dependency execution
Level-order: run ready jobs with no pending parents; on parent complete, unblock children—event-driven wake is better than polling deps every second.
If you remember one thing: DB-as-queue is simpler until the tick becomes hot; external queue adds ops but smooths bursts.
Detailed design
Write path (schedule job)
- Client submits job with payload, schedule, idempotency key.
- API inserts row
PENDING, computes firstnext_run_at, returns job_id. - For DAG jobs, dependency rows link to parents—all parents done before enqueue.
Read path (worker claim)
- Worker receives message or polls DB with
locked_until < now(). - UPDATE … WHERE id=? AND lease expired → set
RUNNING,locked_until=now+lease. - Execute; on success COMPLETE; on failure retry with backoff or DLQ.
Cron evaluation
Leader runs every second (or coarser): for each cron row, materialize next occurrence if due—insert into ready queue with dedupe (cron_id, occurrence_ts) unique.
If you remember one thing: Write path persists; worker path claims with lease; cron materializes with dedupe.
Key challenges
- Double dispatch: Two schedulers both enqueue same cron tick—unique keys and fencing mitigate.
- Lost work: Crash before persist—ack only after durable enqueue; outbox pattern for API → queue atomicity.
- Stuck RUNNING: Worker dies—lease expires; job retries—at-least-once visible to business (idempotency).
- Thundering herd at :00: Many crons fire same minute—jitter spreads load.
- Ordering vs fairness: Strict priority can starve low priority—aging or weighted fair queueing.
If you remember one thing: Double dispatch, lost work, stuck RUNNING, and :00 herds are the named tensions—not “pick Kafka.”
Scaling the system
- Workers: Horizontal; auto-scale on queue lag (oldest message age).
- Scheduler: Shard tick by key range; read replicas for reporting—not for claim path without careful locking.
- DB: Partition jobs table by tenant or time; hot tenants isolated.
- Global schedules: Region-local schedulers for data residency; cross-region cron is rare—clarify authority.
If you remember one thing: Scale workers on queue age; shard scheduler tick before one leader melts the primary.
Failure handling
| Failure | Effect | Mitigation |
|---|---|---|
| Worker crash mid-job | Duplicate run after lease expiry | Idempotent handler; external dedupe |
| Queue backlog | Growing lag | Scale workers; shed low-priority; alert on age |
| Scheduler leader dies | Tick pauses | Failover seconds; missed ticks catch up with rate limit |
| User callback 500 | Retry storm | Exponential backoff, max attempts, DLQ |
Degraded UX: Jobs late; outage is lost jobs or unbounded retry—unacceptable—durability is the product.
If you remember one thing: Worker death → lease expiry → retry is normal; poison goes to DLQ, not infinite loops.
API design
| Endpoint | Role |
|---|---|
POST /v1/jobs | Create; body: schedule, payload, retry, idempotency_key |
GET /v1/jobs/{id} | Status, next_run_at, attempts |
DELETE /v1/jobs/{id} | Cancel future runs; optional kill running with SIGTERM story |
POST /v1/jobs/{id}/trigger | Manual run (admin) |
Headers: Idempotency-Key on create; X-Request-ID for tracing.
Webhook callback (worker → user system):
| Field | Role |
|---|---|
X-Job-Id | Correlation |
X-Attempt | Retry count |
X-Scheduler-Signature | HMAC verify |
Flow diagram:
POST /v1/jobs ──► 202 Accepted + job_id
│
Scheduler tick ──► ready queue ──► Worker ──► POST https://customer/callback
│
200 ─► ack
5xx ─► retry w/ backoff
If you remember one thing: Create returns 202; execution is async with idempotency keys and signed callbacks.
Production angles
Job systems are distributed clocks with unreliable workers and customers who never read your idempotency contract. The scheduler guarantees delivery attempts, not business correctness—that boundary is where every interesting postmortem starts.
Jobs “randomly” ran twice
What users saw — Double charges, duplicate emails, duplicate inventory holds. The customer swears they clicked once. Logs show two HTTP callbacks with different X-Attempt values—or retries after ambiguous timeouts.
Why — Queues are at-least-once. Visibility timeouts and network blips cause redelivery. A slow 500 from the customer makes your worker retry while the first effect actually committed. Exactly-once execution is not a feature of HTTP callbacks.
What good teams do — Document the contract loudly. Dedupe table on (job_id, logical attempt) or business idempotency key. Pass fencing tokens or monotonic lease versions so stale workers cannot commit late effects. The customer must make POST callbacks safe under retry.
Queue age spikes every hour
What users saw — Depth graphs show a comb every sixty minutes. p99 time-to-first-execution breaches SLO even though steady-state looks fine. Worker CPU spikes together; downstream databases see synchronized load.
Why — Millions of jobs scheduled at :00 without jitter. Materialization returns huge batches at once. Autoscaling lags the spike. “Midnight UTC cron” is a classic footgun for global products.
What good teams do — Jitter within a window (for example ±5 minutes). Separate queues by tier and SLO. Pre-scale workers before known peaks. Alert on queue age before CPU—age is the user-visible pain.
Scheduler DB hot: tick queries melt the primary
What users saw — Primary CPU high on a “simple” SELECT ... WHERE next_run_at < now(). Replication lag grows. Dispatch slows and cascades into age SLO breaches.
Why — Missing composite index on (status, next_run_at). Table bloat. Too many rows stuck in READY. Polling scheduler scans history. Wrong partitioning for time-range queries.
What good teams do — Index for the claim pattern you actually use. Partition due jobs by time or shard by tenant. Move to indexed lease claims with SKIP LOCKED where supported. Cap batch size per tick.
Backpressure: enqueue faster than execute
What users saw — Ready queue depth ramps. Age SLO goes red while worker CPU still has headroom—often downstream callback latency or DB locks, not local CPU.
Why — Customer HTTP p99 grew. Global concurrency limit too low. DLQ replay added load. Throughput is always end-to-end.
What good teams do — Scale workers or shed low-priority ingress. Delay cron materialization when backlogged. Isolate noisy tenants. Measure schedule skew, attempt histogram, DLQ rate, queue age, tick duration.
[ Enqueue rate >> process rate ]
→ ready queue depth ↑
→ age SLO red before CPU red
→ scale workers OR shed load OR delay cron materialization
How to use this in an interview — Separate “scheduler delivered the attempt” from “business effect happened once.” Close with idempotency keys for effects and a fencing story if the room pushes on double execution.
Bottlenecks and tradeoffs
Simplicity vs scale
The tension — DB polling scheduler has fewer moving parts until the tick becomes the bottleneck.
What breaks — Primary melts on next_run_at scans; dispatch lag grows.
What teams do — Start DB-as-queue; move ready work to external queue when tick or claim contention hurts.
Say in the interview — Name when you would add Kafka/SQS—not on day one by default.
Strong timing vs queue latency
The tension — “Run exactly at T” conflicts with queue-based execution.
What breaks — Jobs arrive seconds late during backlog.
What teams do — SLO as “within N seconds of T”; jitter cron to avoid herds.
Say in the interview — Honest latency bar beats pretending nanosecond cron on a queue.
History retention cost
The tension — Detailed execution logs help debug but cost money at TB/year.
What breaks — Storage bills climb; queries slow.
What teams do — TTL archive to cold storage; retain all failures longer than successes.
Say in the interview — Partition executions by time; sample success detail if needed.
If you remember one thing: Every tradeoff ties back to tick cost, queue age, or duplicate effects.
What should stick
You do not need to memorize every box. After this guide, you should be able to:
- When vs who — Scheduler decides when; workers claim and run with leases.
- At-least-once wire, idempotent effects — Retries are normal; business dedupe is mandatory.
- Cron dedupe on failover — Unique
(cron_id, occurrence_ts)or fencing—not two leaders firing midnight billing. - Leases for stuck work — Worker dies → lease expires → retry; poison → DLQ.
- Measure queue age — Depth and oldest-message age beat CPU for user-visible pain.
Tell it in the room: “Jobs persist with next_run_at. A leader tick enqueues due work. Workers claim with a lease, call the customer webhook, ack or retry with backoff. Cron materializes each occurrence once. Handlers must be idempotent because delivery is at-least-once.”
Reference diagram
What interviewers expect
Scheduler service; priority queues; worker lease; DLQ; idempotent job design.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Cron scale?
- Exactly-once?
- Priority?
- Worker failure?
- vs Airflow?
Deep-dive questions and strong answer outlines
Architecture?
API enqueue → metadata DB → priority queues → workers pull lease → heartbeat extend.
Cron?
Scatter start times; shard cron service; store next_run.
Retry?
Exponential backoff; max attempts; DLQ with alert.
Exactly-once?
At-least-once + idempotent handlers or outbox pattern.
Long jobs?
Separate queue; checkpoint progress; split into subtasks.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Kubernetes enough?
A: K8s cron is subset; discuss distributed queue.
Q: DAG workflows?
A: Airflow layer above simple scheduler—scope.
Q: Delayed jobs?
A: Visibility timeout queue.
Q: Observability?
A: Job status UI + metrics on queue depth.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.