System design interview guide
Booking Waitlist System Design
Concert sells out in 90 seconds but 200K fans stay on waitlist hoping for cancellations—when one seat frees, five notification workers must not sell it twice. Waitlist queue, hold TTL, and fair notify order are the product.
Problem statement
Sold-out booking with FIFO waitlist and cancellation-driven offers.
Introduction
The concert sold out in four minutes. You joined the waitlist at position 847. Three weeks later your phone buzzes: "You have 15 minutes to claim your ticket." You tap Accept—but the app spins. Someone else already got the seat.
A waitlist is not a Redis LIST. It is a durable priority queue with business rules glued to inventory events. The interesting failures are duplicate offers for the same seat, orphaned offers after worker crashes, and notification gaps.
Interviewers want a clear state machine, per-resource concurrency control, and booking integration that survives retries.
If you remember one thing: Per-resource serialized workflow + durable notifications + booking service owns inventory truth.
How to approach
Define states and transitions on paper before you draw boxes.
- Ask scope — FIFO vs loyalty priority? Payment in the offer window? Exact position visible to users?
- State machine —
WAITING → OFFERED → ACCEPTED / DECLINED / EXPIRED. - One cancellation — Capacity released → one offer → accept or expire → promote next.
- Failures — Notify fails, booking API returns 503, user leaves while offered.
- Bulk cancel — Weather cancels 500 seats—storm of promotions needs backpressure.
In the room: "I'll draw the waitlist state machine, walk one cancellation freeing one slot through offer and accept, then failure paths and booking integration."
If you remember one thing: The booking service owns inventory truth—the waitlist orchestrates people, not seats.
Interview tips
Five exchanges that come up often. Each has what you might say, what they push on, and where to land.
Outbox for notifications
You: "After we create an offer, we call SendGrid synchronously."
They ask: "Email API is slow—what if the worker crashes mid-send?"
Land here: Insert offer row and outbox event in the same transaction. A relay worker pushes to email/push—reliable handoff even if the notifier retries.
Per-resource serialization
You: "We process all cancellation events in parallel for speed."
They ask: "Two workers free the same seat—do two people get offers?"
Land here: One promotion pipeline per resource—shard lock, partition consumer keyed by resource_id, or idempotent event processing with event_id unique constraint.
Idempotency on accept
You: "User double-taps Accept—we book twice."
They ask: "What stops duplicate charges or duplicate reservations?"
Land here: Idempotency-Key on accept_offer. Booking service dedupes final reservation creation. At-least-once notifications are OK if downstream dedupes.
Position transparency
You: "We show exact rank #847 to everyone."
They ask: "What stops bots from gaming the queue?"
Land here: Opaque bands or estimated wait time are valid product choices. If you show exact rank, document how leave and priority inserts shift positions—and audit every change.
Bulk cancel storm
You: "We offer every freed seat immediately."
They ask: "Weather cancels a festival—500 slots return at once."
Land here: Wave promotions or rate-limit notifications to match provider TPS. Fairness policy: strict FIFO per resource vs batched waves—state it.
If you remember one thing: After each push, name one mechanism—outbox, per-resource lock, idempotency key—not "we'll use a queue."
Capacity estimation
| Load | Implication |
|---|---|
| Waitlist depth per hot event | Millions of rows—index (resource_id, position) or heap by score |
| Offer churn | Short TTL rows and many transitions—archive terminal states to cold storage |
| Notification fan-out | Bursts when many slots return—queue workers sized to provider TPS |
So we cannot: send every email synchronously from the API thread. Promote in batches with backpressure when cancellations spike.
If you remember one thing: Notification burst rate must match provider limits—not just worker count.
High-level architecture
What breaks if you use only Redis LIST
No durability, no audit trail, no explainable state when support says "I was next." Duplicate workers without per-resource locks double-offer the same seat.
What works: state machine + outbox + booking integration
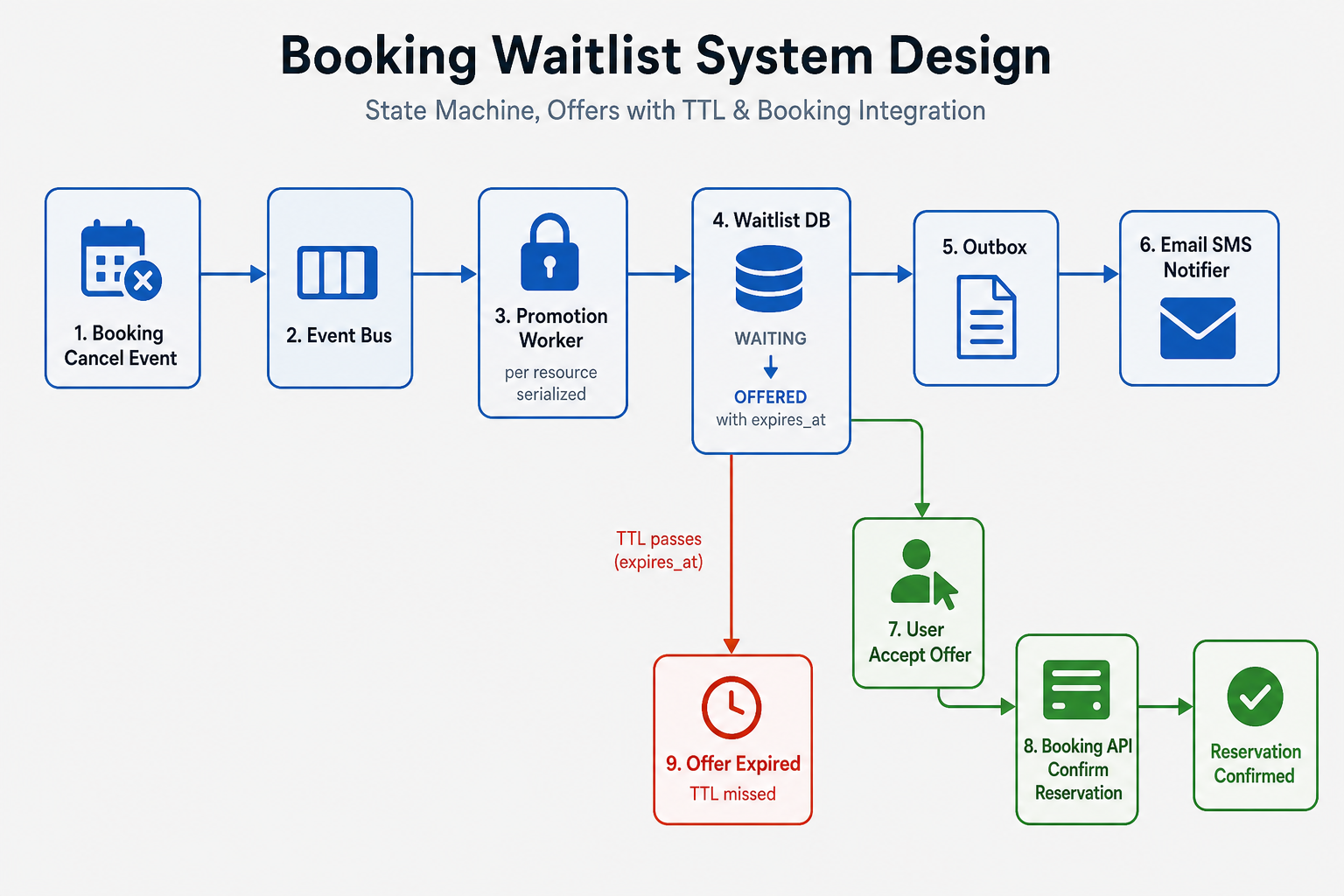
The waitlist API persists rows in WAITING. The inventory service emits CapacityReleased events (from cancellation or admin). A promotion worker (per shard or holding a per-resource lock) claims the event, opens a transaction, selects the next waiter, creates an OFFERED row with expires_at, commits, and writes an outbox row. The notifier sends an offer link with a signed offer_token. The user calls POST …/accept → the booking service creates the reservation; the waitlist moves to ACCEPTED or DECLINED.
[ Booking cancel ] --> event bus --> Promotion worker (per resource serialized)
|
v
[ Waitlist DB ]
WAITING -> OFFERED (expires_at)
|
outbox row
v
[ Email/SMS worker ]
|
User clicks --> POST /offers/{id}/accept --> Booking API (hold + confirm)
In the room: Emphasize that the booking service owns inventory truth—the waitlist orchestrates people, not seats, unless scope says otherwise.
If you remember one thing: Offer creation and outbox write share one transaction—notification is async but durable.
Core design approaches
Storage
Relational rows per (user, resource) with state, joined_at, score, offer_id. A unique constraint prevents duplicate joins.
Ordering
FIFO: joined_at plus a monotonic tie-breaker.
Priority: score descending, joined_at ascending—watch starvation; consider aging boosts for old entries.
Integration
Saga: offer accepted → booking creates reservation → on success waitlist terminal ACCEPTED; on failure → decline or retry booking with backoff, then expire offer and promote next.
If you remember one thing: Say FIFO vs priority and what happens when rules conflict with marketing copy.
Detailed design
Join
- Verify the resource is full (or product accepts waitlist-only signup).
INSERTwaitlist rowWAITINGif not exists (unique).- Return a position band or an opaque "you're on the list."
Promotion on capacity
- Consumer receives
CapacityReleased(resource_id, quantity). - For each unit:
BEGIN; lock resource row or useSELECT … FOR UPDATE SKIP LOCKEDon nextWAITINGuser; create offer; set waiter toOFFERED; insert outbox;COMMIT. - Notify asynchronously.
Accept
POSTwithoffer_tokenandIdempotency-Key.- Validate offer not expired and not already terminal.
- Call booking
POST /reservations(internal). - On 201 from booking: mark
ACCEPTED. - On 409 from booking: expire offer and promote next (slot gone).
In the room: Walk cancel event → OFFERED + outbox → accept → booking confirm.
If you remember one thing: Offer TTL and notification latency are one budget—size TTL for p99 delivery plus human reaction time.
Key challenges
For each, say what the user sees if you get it wrong.
- Duplicate offers — Two workers process the same event—idempotent event processing or row locks.
- User leaves while offered — Transition to
CANCELLED_BY_USERor force decline on leave. - Payment step — Tie offer TTL to payment authorization window—coordinate with PSP.
- Fairness under priority — Document precedence rules (VIP vs FIFO tie-break).
If you remember one thing: "I was skipped" is a reputation problem—audit every state transition.
Scaling the system
- Shard waitlist by
resource_idhash or event id. - Single consumer per hot resource (Kafka partition key =
resource_id) for strict ordering. - Backpressure: cap depth of
WAITINGper resource or return 410 when list is full.
If you remember one thing: Hot event = hot resource_id shard—measure promotion lag.
Failure handling
| Failure | What user sees | Mitigation |
|---|---|---|
| Notify fails | No SMS yet; offer in app inbox | Retry with backoff; offer expires independently |
| Booking 503 on accept | Spinner, then error | Retry with bounded attempts; expire and promote next |
| Poison message on bus | Stuck promotion | DLQ plus alert; manual replay |
If you remember one thing: In-app offer inbox is primary—SMS is a hint that may arrive late.
API design
| Endpoint | Role |
|---|---|
POST /v1/resources/{id}/waitlist:join | Join |
DELETE /v1/waitlist/{entry_id} | Leave |
GET /v1/waitlist/{entry_id} | Status and active offer if any |
POST /v1/offers/{id}:accept | Accept (idempotent) |
POST /v1/offers/{id}:decline | Decline |
POST /v1/offers/{id}:accept
| Header / field | Role |
|---|---|
Idempotency-Key | Dedup retries |
payment_method_id | If payment is in scope |
In simple terms: join while full, get offered when capacity frees, accept calls booking API to lock the seat.
Diagram:
POST join --> 201 (entry_id)
...
event CapacityReleased --> worker --> OFFERED + notification
POST accept --> Booking API --> 201 reservation
--> waitlist ACCEPTED
In the room: Walk join → event → offer → accept with idempotency on the last step.
If you remember one thing: Idempotency-Key on accept prevents double booking on double tap.
Production angles
Waitlists are fairness machines disguised as queues. Production breaks when priority rules conflict with FIFO expectations, when promotion workers lag user patience, and when offers expire in the notification channel slower than the TTL.
"I was skipped" — fairness vs opaque reordering
What users saw — Social media outrage, chargebacks, executive escalation. Audit shows a priority-tier insert or buggy sort key. Users screenshot position numbers that changed without explanation.
Why — Product adds VIP or loyalty boosts without documenting conflicts with FIFO marketing. Concurrent capacity events recompute ranks; off-by-one bugs skip rows under pagination cursors.
What good teams do — Immutable audit log per transition (from_state, to_state, reason_code, rule_version). Support replay tool reconstructs position history. Public copy honest about priority lanes. Fairness bugs are P0 even when revenue looks fine.
Offers expire before the user sees them
What users saw — SMS arrives after offer_expires_at. Push throttled by OS. User opens email hours later. Conversion tanks; ops extends TTL ad hoc and breaks inventory math.
Why — TTL tuned for happy-path latency. Provider delay, DND, spam filters. Worker lag between OFFERED and notification enqueue eats the human reaction budget.
What good teams do — In-app inbox as primary surface. Size TTL ≥ p99 notification latency plus reaction time. Monitor time from CapacityReleased to delivered by channel. Extend offers idempotently with audit—not silent clock changes.
Promotion backlog: cancellations spike faster than workers
What users saw — WAITING users see stale position. Offers arrive in bursts hours after inventory freed. Queue depth ramps while CPU looks fine—often DB lock contention on one hot shard.
Why — Many cancellations enqueue jobs faster than workers drain. Hot resource row serializes updates. Naive SELECT FOR UPDATE over large ranges.
What good teams do — Scale workers with partition by resource_id. Wave promotions to smooth notification spikes. Measure lag from CapacityReleased to OFFERED, offer expiry without open, booking failure rate on accept.
[ Many cancellations ] --> promotion worker falls behind
--> WAITING users get offers late (SLA miss)
--> scale workers OR shard hot resources OR wave promotions
How to use this in an interview — Pair auditability of line position with channel latency assumptions. Close with idempotency on accept—a double tap must not book twice.
Bottlenecks and tradeoffs
Strict FIFO vs business priority
The tension — VIP lanes improve revenue; FIFO marketing promises anger users when order changes.
What breaks — "I was skipped" tickets and social posts.
What teams do — Document rules; audit every promotion; honest public copy.
Say in the interview — Name your ordering policy and starvation mitigations (aging boosts).
Transparency vs gaming
The tension — Exact position builds trust; bots optimize join timing.
What breaks — Gaming, scalpers, support load.
What teams do — Opaque bands, rate limits on join, CAPTCHA on hot events.
Say in the interview — Pick visible rank or opaque list and defend it.
If you remember one thing: Offer TTL must include notification p99—not just human click time.
What should stick
You do not need to memorize every box. After this guide, you should be able to:
- State machine —
WAITING → OFFERED (TTL) → ACCEPTED / DECLINED / EXPIRED—every transition auditable. - Per-resource serialization — One promotion pipeline per concert/flight/slot pool—no double offers.
- Outbox notifications — Offer row + outbox in same transaction; SMS/email async but durable.
- Booking integration — Accept calls booking API; inventory truth lives there—not in the waitlist.
- Idempotency on accept — Double tap must not double book or double charge.
Tell it in the room: "Cancellation emits CapacityReleased. One worker per resource picks next WAITING user, creates OFFERED with expiry, outbox for notify. User accepts with idempotency key—booking service confirms seat. On timeout or decline, promote next. TTL sized for notification latency plus reaction time."
Reference diagram
What interviewers expect
FIFO queue; atomic pop on inventory; hold TTL; idempotent notify.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Fairness?
- Cancel releases seat how?
- Notify storm?
- Hold time?
- Multiple waitlists?
Deep-dive questions and strong answer outlines
Join waitlist?
Persist position or use Redis ZSET score=timestamp; cap queue size.
Seat freed?
Atomic claim seat → pop next waitlist user → send purchase link token TTL 15m.
Double sell?
Seat status CAS; only one waiter wins; others stay queued.
Notify many?
Notify top K in case of multiple seats; batch SMS/push with rate limit.
Expire hold?
Cron releases seat back to pool or next waiter.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Priority VIP?
A: Separate queue or score bump—state policy.
Q: Same as ticketing?
A: Waitlist is extension after sellout.
Q: Pay deposit on waitlist?
A: Optional hold fee—refund rules.
Q: Ghost users?
A: Confirm email before queue position counts.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.