System design interview guide
Notification System Design
Flash sale push goes to 40M devices in one minute—APNs/FCM rate limits bite while email backlog grows in a queue that loses ordering for password resets. Multi-channel delivery, preferences, and idempotent templates separate real notification systems from "call FCM in the API.
Problem statement
Multi-channel notifications: queue, preferences, provider rate limits.
Introduction
You reset your password. The app says "code sent." Five minutes later—nothing. You request again. Now two codes arrive and neither works.
Notification platforms are distributed queues with policy. Interviewers want backpressure, per-channel failure modes, and preference evaluation before fan-out—not a diagram with three arrows to SendGrid.
Weak answers treat "delivery" as one boolean. Strong answers separate enqueue (must succeed fast) from delivery (retries, quotas, 410 Gone on dead tokens).
If you remember one thing: Enqueue fast and durable; deliver async with lanes, retries, and idempotency—provider "delivered" is not "user saw it."
How to approach
Split the problem before you name Kafka.
- Ask scope — Marketing blast vs transactional only? Scheduling? In-app inbox?
- Ingress — Persist row + ack in milliseconds—do not wait for FCM.
- One send — Enqueue → prefs → template → channel worker → provider.
- Lanes — Transactional vs marketing—separate queues or priority.
- Ops — Queue age, 410 token sweep, stale opt-out cache.
In the room: "I'll split enqueue from delivery, walk one transactional push, then rate limits, retries, and why marketing must not starve OTP."
If you remember one thing: 202 Accepted means we saved the job—not that Apple delivered it to the user's eyes.
Interview tips
Five exchanges that come up often. Each has what you might say, what they push on, and where to land.
Guaranteeing delivery
You: "We guarantee exactly-once delivery to every device."
They ask: "APNs retries, email bounces, user uninstalls the app—what do you actually promise?"
Land here: Aim for at-least-once with idempotency_key per logical notification. Client or inbox dedupes. Be honest: end-to-end exactly-once to humans is hard.
Provider rate limits
You: "We fan out one HTTP call per user in a loop."
They ask: "You need to notify one million users—what happens to FCM quotas?"
Land here: Batch where APIs allow. Throttle per provider account with token buckets. Partition work across workers—never one synchronous loop.
User preferences
You: "We cache preferences in Redis forever for speed."
They ask: "User opted out—marketing still arrives for three minutes. Regulator calls."
Land here: Evaluate prefs before expensive fan-out. Short TTL plus invalidation on update. For marketing flags, consider pessimistic read. Audit pref_version used at send time.
Duplicate notifications
You: "Retries are disabled so users never see duplicates."
They ask: "Worker crashes after send but before ack—do you lose the OTP?"
Land here: Retries are required—use idempotency_key (e.g. order_id + type) so retries do not create duplicate user-visible alerts if client dedupes poorly.
Transactional vs marketing priority
You: "One queue for all notifications—simpler ops."
They ask: "Black Friday marketing spike—password reset waits behind it?"
Land here: Separate queues or priority classes with budgets. Transactional bypasses marketing throttle. Shed marketing first during incidents.
If you remember one thing: After each push, name one mechanism—idempotency key, separate lane, token sweep—not "we'll scale workers."
Capacity estimation
| Dimension | Implication |
|---|---|
| 100M+ notifications/day | Partition by tenant or hash(user) for fairness |
| Peak 5K/s enqueue | Kafka/SQS with provisioned throughput or autoscale consumers |
| Provider caps | Token bucket per provider account; smooth bursts |
| Device registry | Hundreds of millions of rows—TTL stale tokens |
So we cannot: call APNs once per user in a single synchronous loop from the API. Batch, async, throttle.
If you remember one thing: Provider quotas are the real ceiling—not your worker CPU.
High-level architecture
What breaks if enqueue waits for delivery
API time-outs when FCM is slow. Retries without idempotency spam users. One marketing blast blocks OTP in a shared queue.
What works: durable ingress, async lanes, provider adapters
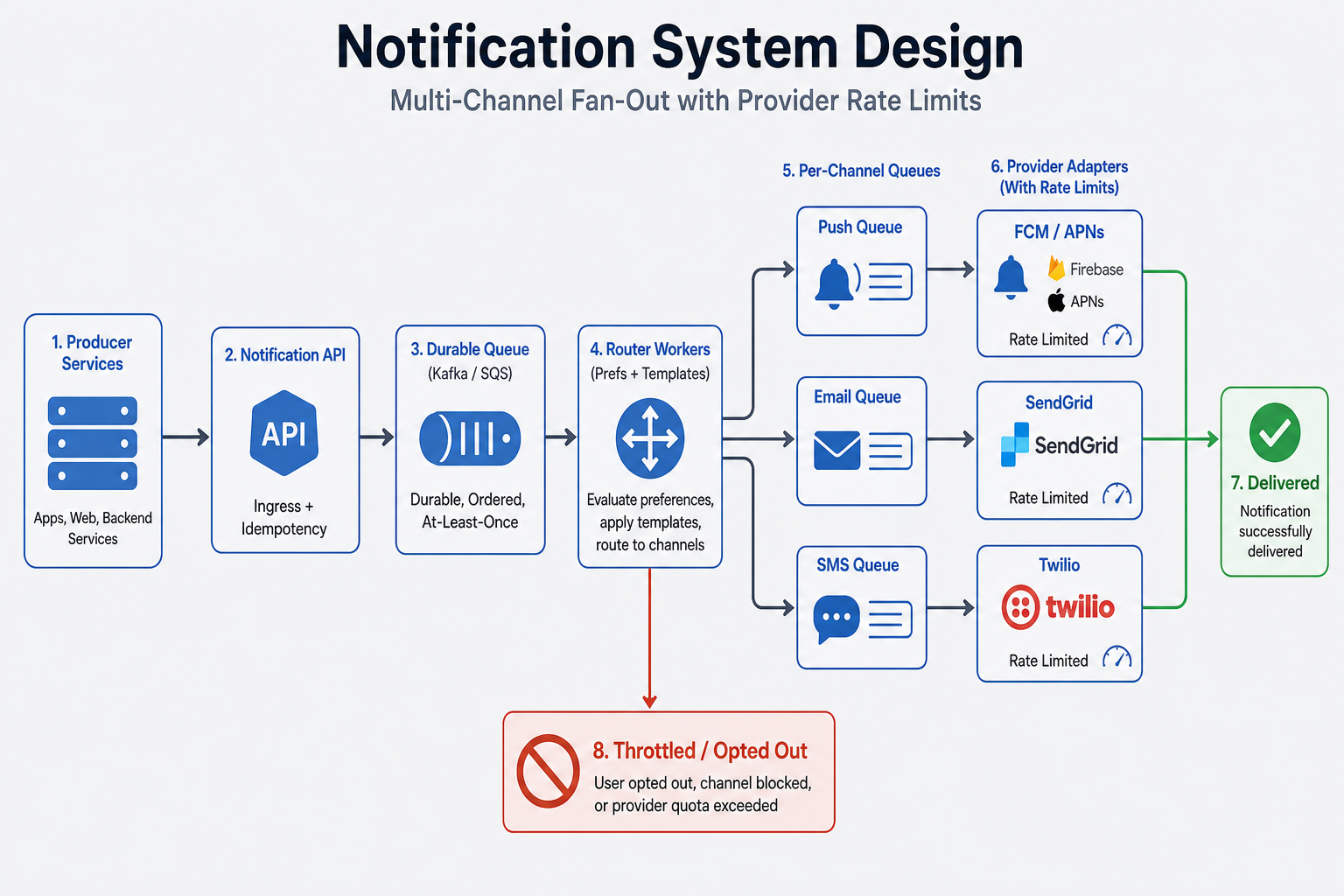
Producer services call Notification API with { user_id, template_id, vars, channel_hint, idempotency_key }. API persists a notification row and enqueues to Kafka/SQS. Router workers load prefs and template, drop if opted out, route to per-channel queues. Channel workers respect provider rate limits, call vendor APIs, record attempts and terminal status. Scheduler ticks delayed jobs into the same pipeline.
Who owns what:
- Ingress API — Auth between services; idempotency; schema validation.
- Preference / device registry — Hot reads; cache with version.
- Template service — i18n, MJML/HTML for email.
- Channel workers — Adapter code per provider; circuit breakers.
[ Producers ] --> [ Notification API ] --> [ Durable queue ]
|
router workers (prefs + template)
|
+--------------------+--------------------+
v v v
[ Push queue ] [ Email queue ] [ SMS queue ]
| | |
v v v
FCM / APNs SendGrid SES Twilio etc.
Scheduled: [ Scheduler ] --> same enqueue path
In the room: Say at-least-once delivery and idempotency keys so retries do not become duplicate SMS.
If you remember one thing: Three layers—ingress, router, channel workers—each with different failure modes.
Core design approaches
Transactional vs marketing
Transactional: OTP, receipt—often bypass marketing throttle with abuse checks only.
Marketing: Stricter frequency caps, unsubscribe enforcement, separate quota.
Single vs multi-queue
Separate queues reduce head-of-line blocking—OTP never waits behind a blast.
If you remember one thing: Lane isolation is a product SLO decision—not an ops nice-to-have.
Detailed design
Write path (enqueue)
- Validate caller; insert
notificationsrowPENDING. - Enqueue
{notification_id}to stream. - Return 202 with id—do not wait for FCM.
Read path (delivery)
- Worker pulls batch.
- Load prefs—if channel disabled, mark
SUPPRESSED. - Render template; send via provider.
- Record attempt; on 429/5xx requeue with backoff; on 410 delete token.
In the room: Walk POST → 202 → worker → provider → attempt row.
If you remember one thing: SUPPRESSED is a valid terminal state—auditable opt-out, not silent drop.
Key challenges
For each, say what the user sees if you get it wrong.
- Quota — One noisy tenant burns shared provider account—per-tenant caps.
- Duplicate user-visible notifications — Idempotency key per logical event (
order_id + type). - Timezone for scheduled reminders — Store UTC + IANA zone.
- Hot incident — Everyone enqueues at once—admission control or shed non-critical categories.
If you remember one thing: Lost OTP is outage; delayed marketing is degraded UX.
Scaling the system
- Horizontal workers per channel; partition Kafka by
tenant_idoruser_id. - Isolate noisy tenants to dedicated queues or lower priority.
- Regional FCM/APNs endpoints—pin workers near provider regions if needed.
If you remember one thing: Scale consumers on queue age, not only CPU.
Failure handling
| Scenario | What user sees | Mitigation |
|---|---|---|
| Provider 429 | Delayed notification | Exponential backoff; jitter; circuit open → pause partition |
| Invalid token | Push never arrives | 410 → remove token; do not retry forever |
| Template render error | Nothing sent | DLQ; alert—bug not transient |
| Queue backlog | OTP minutes late | Scale consumers; shed marketing first |
Degraded UX: Delayed marketing.
Outage: Lost OTP or silent total failure on transactional lane.
If you remember one thing: DLQ poison templates—do not block the whole partition forever.
API design
| Endpoint | Role |
|---|---|
POST /v1/notifications | Enqueue; body: user_id, template_id, data, channels?, send_after? |
GET /v1/notifications/{id} | Status and attempts |
POST /v1/users/{id}/preferences | Update prefs (also from product UI) |
POST /v1/notifications
| Field | Role |
|---|---|
idempotency_key | Dedup logical sends |
category | transactional | marketing — routing and caps |
template_id | Which template version |
In simple terms: save the job, return 202, workers deliver later with prefs and retries.
Internal flow diagram:
POST /v1/notifications --> DB row + queue message --> 202 Accepted
|
v
router --> prefs OK? --> channel worker --> provider
| no --> SUPPRESSED (still auditable)
Errors: 400 bad template; 429 tenant over quota; 503 enqueue path unhealthy—rare if queue is healthy.
In the room: Walk POST → 202 → router → channel worker. Mention SUPPRESSED when opted out.
If you remember one thing: category routes to lane and rate limit—transactional vs marketing.
Production angles
Notification platforms sit between your reliability and Apple's, Google's, ESPs', and carriers'. The worst incidents are silent: queues age, marketing drowns transactional, email reputation collapses, and compliance discovers stale opt-outs in cache.
Push "delivered" but the user never sees it
What users saw — Provider dashboards show delivered. User claims no OTP. MFA support tickets spike. iOS Focus modes swallow categories silently.
Why — Delivery to device is not visibility in UI. Tokens stale after reinstall. Battery optimization defers FCM. Email lands in Promotions when SPF/DKIM slipped. Shared domain reputation poisons receipts.
What good teams do — In-app inbox plus SMS fallback for high-value transactional (cost-aware). Separate subdomains for marketing vs receipts. Metrics on delivery by provider error code—not only HTTP 202 from your API.
Email reputation death spiral after a "small" campaign
What users saw — Spam placement spike. Open rates collapse. Gmail Postmaster turns red. Product wants to re-send volume—making it worse.
Why — Blast without list hygiene. Ignored hard bounces. Shared IP with bad neighbors. Skipped domain warm-up.
What good teams do — Suppression list as source of truth. Automatic pause on bounce-rate SLO. Segment transactional from marketing at architecture level. SES/SendGrid reputation is borrowed—not owned.
Queue backlog: transactional starves while workers drown in marketing
What users saw — Transactional p99 breaches. Marketing spike fills queue. Age SLO red before CPU maxes. DLQ climbs—often provider 429 during viral moment.
Why — Shared infrastructure without lane isolation. Large payloads block workers. No global concurrency cap per tenant and channel.
What good teams do — Separate queues for transactional vs marketing. Shed lower priority first. Dynamic rate limits aligned to provider quotas. Measure queue age by lane.
[ Traffic spike ] --> queue depth grows --> age SLO red
--> shed marketing --> protect transactional lane
Stale preferences in cache — compliance incident
What users saw — User opts out. Marketing still arrives for minutes. Regulator letter follows.
Why — Aggressive caching without invalidation on update. Eventual consistency between profile service and notification router.
What good teams do — Short TTL plus explicit invalidation on change. Pessimistic read for marketing flags. Audit every send with pref version used.
How to use this in an interview — State that channel delivery ≠ human attention. Lanes and reputation are first-class. Stale opt-out cache is worse than slow email.
Bottlenecks and tradeoffs
Throughput vs cost
The tension — More workers and provider spend vs budget caps.
What breaks — Queue age SLO red during peak.
What teams do — Autoscale on age; throttle marketing first.
Say in the interview — Name which lane gets budget when provider throttles.
Strong prefs vs latency
The tension — Cache prefs for hot path speed.
What breaks — Stale opt-out → compliance incident.
What teams do — Short TTL + invalidation; audit pref version at send.
Say in the interview — Marketing prefs are not the same cache policy as static assets.
If you remember one thing: Protect transactional lane first; shed marketing; sweep dead tokens.
What should stick
You do not need to memorize every box. After this guide, you should be able to:
- Enqueue vs deliver — API returns 202 fast; workers retry with backoff—different SLOs.
- Lanes — Transactional and marketing separate queues—OTP never waits behind blast.
- Idempotency —
idempotency_keyper logical event—retries without duplicate SMS. - Prefs before fan-out — Opt-out enforced in router; audit pref version at send.
- Provider reality — 410 token sweep; 429 backoff; "delivered" ≠ user saw it.
Tell it in the room: "Producers POST with idempotency key—we persist and enqueue, return 202. Router checks prefs and template, routes to per-channel queues. Workers throttle to provider quotas, record attempts, retry 5xx with jitter, delete dead tokens on 410. Transactional and marketing are separate lanes—shed marketing first in incidents."
Reference diagram
What interviewers expect
Event queue; worker pools per channel; idempotency keys; preference service; DLQ.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Push vs email?
- Scale broadcast?
- Failures?
- User opt-out?
- Priority?
Deep-dive questions and strong answer outlines
Architecture?
Event → notification service → channel queues (push/email/sms) → provider adapters with retry.
Mass push?
Shard campaign into batches; respect provider tokens/sec; collapse duplicates.
Preferences?
Per-user channel flags checked before enqueue; quiet hours delay non-urgent.
Idempotency?
dedupe_key per event+user; store sent log TTL.
Transactional priority?
Separate priority queue; marketing yields when backlog high.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Build APNs?
A: Integrate providers; focus orchestration.
Q: In-app only?
A: Still need inbox store + websocket.
Q: Scheduling?
A: Delayed queue with visibility timeout.
Q: Analytics?
A: Async delivery events stream.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.