System design interview guide
Distributed Cache System Design
Flash sale starts and one product id owns a Redis shard—CPU looks fine while the database melts. The interview is consistent hashing, eviction, replication lag, and cache-aside invalidation, not memorizing RDB flags.
Problem statement
Distributed in-memory cache: partition, replicate, evict, survive failures.
Introduction
A flash sale starts. One product id is in every cart. Your cache cluster shows healthy CPU—but the database catches fire and checkout fails for everyone.
A distributed cache is fast mutable state spread across machines. The interview is not “Redis vs Memcached trivia.” It is how clients find the right shard, what moves when a node joins, what replicas promise (and do not), and what happens when a hot key or TTL expiry turns the cache into a load generator for the database.
Weak answers say “we add Redis.” Strong answers separate routing (hash ring, virtual nodes) from data plane (GET/SET on primaries) and name cache-aside, invalidation, and thundering herd.
If you remember one thing: A cache protects the DB only if you design routing, eviction, and miss storms—not just hit ratio.
How to approach
Start with one machine: TTL, eviction (LRU/LFU), memory limit.
Add sharding: consistent hashing + virtual nodes so load stays even.
Add replication: async copy, failover, stale read rules.
End with cache-aside: who loads on miss, who deletes on DB update, how you stop herd on expiry.
In the room: “Single-node semantics, then hash ring, then replica lag, then cache-aside invalidation and stampede control.”
If you remember one thing: Order beats feature lists—routing before persistence flags.
Interview tips
Five questions that expose shallow cache answers.
Modulo hashing
You: “We hash the key mod number of servers.”
They ask: “You add one server—what happens to every key?”
Land here: Almost all keys move—cache storm + DB spike. Consistent hashing moves only keys in the wedge near the new token; virtual nodes balance load across physical machines.
Invalidate on update
You: “When the DB updates, we invalidate the cache.”
They ask: “One product row maps to fifty cache keys—how?”
Land here: Delete affected keys (or version stamp in value); pattern invalidation is hard at scale—TTL as safety net; document eventual staleness window.
Read-after-write
You: “We read from any replica for speed.”
They ask: “User saves profile, refreshes, sees old name—why?”
Land here: Replication lag. Critical keys: read primary, sticky routing, or version check in value; say what is OK to be stale (display name) vs not (balance).
Thundering herd
You: “TTL keeps data fresh.”
They ask: “Viral key expires—what hits the database?”
Land here: Thousands of simultaneous misses. Singleflight per key, TTL jitter, probabilistic early refresh, stale-while-revalidate where product allows.
Cache vs database
You: “The cache is our source of truth.”
They ask: “Primary crashes—what did we lose?”
Land here: Cache is ephemeral for most workloads; DB is truth. Persistence (RDB/AOF) trades durability for fork latency on big heaps—name p99 impact if you mention it.
If you remember one thing: Tie every tip to one failure mode—rebalance storm, stale replica, herd, split brain.
Capacity estimation
| Topic | Anchor | Implication |
|---|---|---|
| Working set | 100 GB aggregate (illustrative) | Eviction pressure; hot vs cold key skew |
| QPS | 10M ops/s | Per-node ceiling; pipelining; connection limits |
| Value size | ~1 KB average | Network bandwidth; large values need compression or chunking |
| Hot keys | Top 0.01% keys | Replica reads, application-level sharding, or in-process L2 |
Implications: You shard to spread RAM and CPU; you do not solve hot keys only by “adding nodes” if one logical key dominates.
If you remember one thing: Hot keys are a logical problem—sharding spreads averages, not one viral id.
High-level architecture
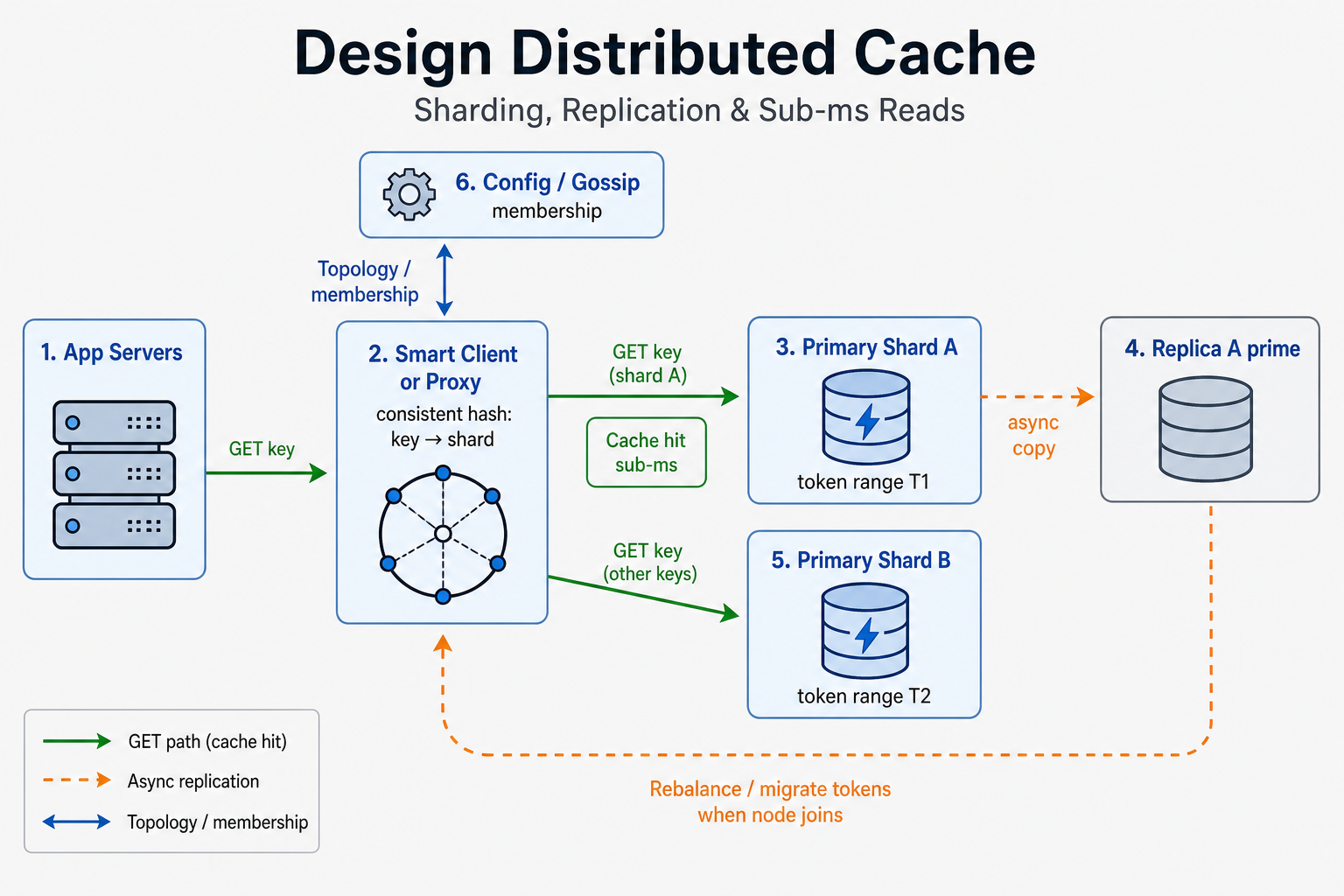
Clients either embed a smart client (knows hash ring) or talk to a proxy (stateless routing). The cluster exposes logical keyspace partitioned into slots or token ranges, each owned by a primary with 1+ replicas. Gossip or a configuration service (etcd-style) publishes membership. Persistence (if any) is async snapshots or append logs—off the critical read path for most designs.
Who owns what:
- Routing layer — Hash(key) → node; handles MOVED/ASK-style redirects when topology changes (Redis Cluster pattern).
- Shard primary — Serializes writes per key (common pattern: single-threaded primary); serves reads or forwards to replica depending on consistency mode.
- Replicas — Async copy from primary; promoted on failover after health checks + epoch bump.
- Control plane — Add/remove nodes, rebalance throttles, placement of primaries across racks/AZs.
[ App servers ]
|
| GET/SET (sync, sub-ms target)
v
[ Smart client or Proxy ] ----membership----► [ Config / gossip ]
|
| consistent hash: key → shard
v
+------------------+ replication +------------------+
| Primary A | ------------------► | Replica A' |
| (token range T1) | | (async, read opt) |
+------------------+ +------------------+
+------------------+ +------------------+
| Primary B | ----------------► | Replica B' |
| (token range T2) | | |
+------------------+ +------------------+
Rebalance (async): new node C → migrate token ranges → throttle → HANDOFF
In the room: Walk one GET: hash → node → memory lookup → optional replica. Then one failover: primary dead → replica promoted → clients refresh topology.
If you remember one thing: GET is hash → primary (or replica with stale rules); rebalance is async and throttled.
Core design approaches
Cache-aside (lazy loading)
App checks cache → on miss, loads DB, sets cache. Simple; invalidation is app’s job when DB updates.
Read-through / write-through
Cache module loads DB on miss (read-through); writes go to cache and DB together (write-through). Stronger consistency; higher write latency.
Write-behind
Writes ack after cache update; async flush to DB—fast but loss risk if cache dies before persist—rare for generic interview unless scoped.
Pick: Most candidates describe cache-aside for read-heavy workloads; mention write-through when stale reads are unacceptable after writes.
If you remember one thing: Cache-aside = app owns invalidation; write-through = stronger consistency, slower writes.
Detailed design
Read path
- Client computes shard (or asks proxy).
- Primary or replica serves GET if stale read OK.
- On miss (cache-aside), app loads DB and SET with TTL.
Write path (cache-aside invalidation)
- App commits DB update.
- App DELETE cache key(s) or bump version embedded in value.
- Next read repopulates—avoid stale by delete vs update carefully (race: read old DB, overwrite new cache—ordering matters).
Atomic ops
INCR, CAS—used for counters and locks. Single primary per key makes this tractable; cross-shard transactions are out of scope for “cache.”
If you remember one thing: On DB update, delete cache keys (or bump version)—order matters to avoid writing stale data back.
Key challenges
- Rebalancing: Moving keys without dual ownership bugs (serving wrong value during migration)—handoff protocols and throttled migrations matter.
- Hot keys: One key → one primary thread or one NIC—YCSB-style skew burns you in benchmarks and production.
- Replication lag: “I wrote then read” flakiness—apps must know which replica they hit.
- Eviction thrash: Memory at max + churning working set → constant eviction + miss storm.
- Split brain: Two primaries after partition—mitigate with quorum, fencing, epoch—at cost of complexity.
If you remember one thing: Rebalance and hot keys hurt more in production than picking LRU vs LFU on day one.
Scaling the system
- Horizontal: Add nodes; only adjacent key ranges migrate (consistent hashing).
- Vertical: Bigger RAM for hot shards—sometimes cheaper than perfect algorithmic fairness.
- Read scaling: Replica reads for read-heavy, eventually consistent keys; primary for linearizable per-key sequence if required.
- Multi-region: Active-active cache is hard (conflicting writes)—often read replicas per region with async replication and stale SLAs.
If you remember one thing: Replica reads scale throughput; primary wins when stale is unacceptable.
Failure handling
| Failure | User-visible | Mitigation |
|---|---|---|
| Primary down | Errors or failover latency | Health checks, automatic promotion, client retry with backoff |
| Replica lag spike | Stale reads | Route critical reads to primary; monotonic reads per session if needed |
| Network partition | Split brain risk | Quorum; minority partition does not accept writes |
| Node add during peak | Latency during migration | Throttle migration; off-peak rebalance |
Degraded UX: Slightly stale data; outage is unavailable cache—often degrade to DB with timeouts (slower, not wrong).
If you remember one thing: Under partition, pick availability + stale for most cache workloads—unless they scope money paths.
API design
Caches expose binary protocols (RESP) or thin REST. Interview clarity matters more than opcode trivia.
Core operations:
| Op | Semantics |
|---|---|
GET key | Return value or miss |
SET key value [EX ttl] | Upsert; optional TTL |
DEL key | Invalidate |
INCR key | Atomic counter |
MGET keys[] | Batch to reduce RTT |
Cluster routing:
| Client view | Behavior |
|---|---|
| Hash ring in SDK | Client sends directly to node; handles redirects |
| Proxy | Clients talk to one endpoint; proxy forwards |
Error semantics: Miss is not an HTTP 404—it is a cache miss; apps distinguish miss vs error (connection reset).
Request flow diagram (GET):
App --GET key--> Client lib --hash--> Primary shard
|
hit --> value
miss (cache-aside) --> DB --> SET --> value
If you remember one thing: A miss is not HTTP 404—it triggers cache-aside load unless you design read-through.
Production angles
Caches are not “faster databases”—they are coordination surfaces where topology, TTLs, and failure fallbacks interact. Veteran operators worry less about hit ratio in steady state and more about what happens the minute a hot key expires, a cluster reshuffles, or a client still points at a dead primary.
p99 latency jumps right after adding capacity
What users saw — You scaled up to “fix” latency; scroll and API got slower for hours.
Why — Rebalance moved huge key ranges at once; NICs saturated; clients still talked to old owners; replicas lagged.
What good teams do — Throttle migration; off-peak adds; pre-warm replicas; alert per-shard imbalance, not average CPU.
Database load spikes while cache “healthy”
What users saw — Brief errors; DB connections maxed; cache dashboards still green.
Why — Thundering herd on one key at TTL expiry; aligned TTLs; no singleflight.
What good teams do — TTL jitter; singleflight in app tier; stale-while-revalidate; correlate evicted_keys, miss ratio, DB QPS.
Inconsistent reads after failover
What users saw — Two tabs show different values; “lost” write reappears after refresh.
Why — Stale topology in clients; replica not caught up; split-brain window.
What good teams do — Push topology updates; read primary for money paths; epoch on failover; document no read-your-writes unless built.
Cache slow → DB stampede
What users saw — Timeouts everywhere; DB overload while team blames “cache cluster up.”
Why — Hot key on single-threaded primary; pool exhaustion; unbounded parallel DB refill on miss.
What good teams do — Circuit-break DB fallback; bulkhead; cap concurrent refill per key; never N identical DB queries for one expiry.
[ Apps spike GETs ] → [ Cache primaries at CPU max ]
→ latency ↑, timeouts
→ some clients fall back to DB → DB overload → worse cache refill
How to use this in an interview — Lead with hot key or herd on expiry. Name singleflight or jitter and what fails first: cache p99 then DB.
Bottlenecks and tradeoffs
Memory vs hit ratio
The tension — Bigger cluster means fewer DB hits; RAM is not free.
What breaks — Diminishing returns; eviction thrash when working set exceeds RAM.
What teams do — Track evicted_keys and tail latency; tier hot data; right-size per shard.
Say in the interview — Cache size is a cost decision with an SLO, not “as big as possible.”
Strong consistency vs cache speed
The tension — Apps want read-your-writes; caches favor speed and partition tolerance.
What breaks — Cross-shard transactions on a cache are the wrong tool.
What teams do — DB as truth; delete on write; short TTL; primary read for critical keys.
Say in the interview — Most caches are eventually stale—say what your app tolerates.
Rebalance vs availability
The tension — Adding nodes should help capacity; migrating keys risks wrong values and latency.
What breaks — Dual ownership during move; redirect storms.
What teams do — Handoff protocol; throttled migration; hinted handoff for reads during move.
Say in the interview — Adding a node is an ops event, not a free horizontal scale button.
If you remember one thing: Caches fail open to the DB in the worst way unless you engineer miss behavior.
What should stick
You do not need every Redis opcode. You should leave knowing:
- Consistent hashing + virtual nodes — Adding a server moves a wedge of keys, not the whole keyspace.
- Cache-aside — App loads on miss; delete (or version) on DB update; TTL as safety net.
- Replication lag — Replicas scale reads; primary when stale is unacceptable.
- Thundering herd — One expiry → many DB hits; jitter + singleflight are mandatory patterns.
- Hot keys — One logical key can saturate one shard; replication or app-level sharding of the key.
Tell it in the room: “Client hashes key to primary via consistent hashing with vnodes. GET hits memory or miss → DB → SET with TTL. On DB write, DELETE cache key. Replica for read-heavy stale-OK data; primary for read-after-write. Viral key: singleflight on miss, TTL jitter. Node add: throttled rebalance with handoff, not big-bang migration.”
Reference diagram
What interviewers expect
Consistent hashing, cache-aside vs write-through, eviction policy, failover, hot key mitigation.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Consistent hashing add node?
- Hot keys?
- Invalidation?
- Strong consistency?
- vs Redis?
Deep-dive questions and strong answer outlines
GET path sharded?
Hash key → token → node; client ring or proxy; replica read optional; single-flight on miss.
Add node?
Consistent hashing moves wedge keys only; virtual nodes balance; rebalance in background.
Cache-aside?
App loads DB on miss; write DB then delete cache key; thundering herd use lock or early refresh.
Primary crash?
Failover replica with epoch/quorum; accept lost in-flight per sync policy.
Hot key?
Replicate hot key to multiple nodes; local in-process cache; split key sub-ranges.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Redis protocol?
A: Behavior matters more than opcode trivia.
Q: Strong everywhere?
A: Usually eventual; per-op quorum if pushed.
Q: Memcached vs Redis?
A: Pure cache vs data structures + persistence options.
Q: CAP?
A: Caches favor availability + stale reads under partition.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.