System design interview guide
Rate Limiter System Design
An API gateway must enforce per-client limits (by user, IP, API key, or route) to protect backends and keep usage fair. The interesting part is doing it at millions of checks per second with sub-millisecond overhead, correctly across many gateway instances, and with honest behavior when the limiter or its store blips—fail open vs closed is a product and security decision you should state, not hide.
Problem statement
You’re designing a rate limiter in front of APIs: enforce configurable limits per client identity (user id, API key, IP, or combination), per route or service, within time windows, with low overhead on every request.
Constraints in plain language. Functionally you must allow or deny (or optionally delay) each request based on usage so far, support multiple limit types (fixed/sliding/token bucket), expose headers for remaining quota, and often whitelist internal callers. Non-functionally the limiter is on the critical path: microsecond to low-millisecond budget, horizontal gateway fleet, and huge aggregate QPS. Scale assumptions typically include millions of checks per second and tens of millions of distinct clients—so memory per key and hot keys matter.
What interviewers reward: a clear algorithm, distributed state story, atomicity, failure mode, and HTTP semantics—not a box labeled “Redis” with no behavior.
Introduction
Your mobile app hits “retry” on a flaky network. Twenty requests leave the phone in one second. Without a limiter, they all reach checkout—and twenty charges are possible. With a bad limiter, each gateway counts locally and the user gets ten times the allowed quota.
Rate limiting is not “increment a counter.” It is shared state under extreme concurrency: every edge node must agree how much quota is left for one logical client.
Interviewers want an algorithm, where state lives, atomic updates, and fail-open vs fail-closed—not a box labeled Redis.
If you remember one thing: Local counters on each gateway multiply allowed traffic; global limits need one source of truth per key (or a honest hierarchical approximation).
How to approach
Negotiate who is throttled: user id, API key, IP, route, or composite key.
Negotiate window length and burst (token bucket vs rigid window).
Walk one request: build key → atomic check in store → allow or 429 → headers.
Then open Redis/Lua. If time allows, add layered limits (user inside tenant inside global) in one round trip.
In the room: “I’ll define the key, pick token bucket vs sliding window, store counters in Redis with Lua atomicity, and say fail-closed on login vs fail-open on catalog read.”
If you remember one thing: One request story before command names.
Interview tips
Five back-and-forths that separate weak from strong limiter answers.
Per-node counters
You: “Each API server keeps its own count.”
They ask: “You have 50 gateways and a limit of 100/min—how many requests actually get through?”
Land here: Up to 50× the limit. Use a central store (Redis cluster) or hierarchical caps: tight local hard limit + global Redis check.
Fixed window only
You: “We reset the counter every minute.”
They ask: “Can a client send 2× the average rate in a few seconds?”
Land here: Yes—burst at window edges. Use token bucket, sliding window, or sub-windows; say the tradeoff in cost vs fairness.
Redis down
You: “If Redis fails, we let everyone through.”
They ask: “Is that OK for password reset and login?”
Land here: Fail-open keeps availability but invites abuse; fail-closed protects auth paths. Different policies per route—state which you pick and why.
429 without guidance
You: “We return 429 when over limit.”
They ask: “What should the client do next?”
Land here: Retry-After (seconds or HTTP-date) plus X-RateLimit-Remaining / Reset. Without backoff hints, clients hammer harder—thundering herd on throttle.
Hot key on one client
You: “We shard Redis randomly.”
They ask: “One OAuth client sends 1M checks/s on one key—what happens?”
Land here: One Redis slot saturates. Mitigate: sub-keys (client:shard:k), dedicated cluster for abusers, or probabilistic counting where exactness is optional.
If you remember one thing: Every answer should name algorithm + atomicity + HTTP contract + failure mode.
Capacity estimation
Rough numbers to anchor the whiteboard (tune in the room):
| Input | Order of magnitude | Design implication |
|---|---|---|
| Aggregate checks/s | 10M+ (illustrative scale) | No O(log N) structures per check unless unavoidable; prefer O(1) key ops |
| Distinct keys | 10²–10⁸ (clients × policies) | Memory per key × TTL discipline; evict idle keys |
| Hot key QPS | Single client abusive or NAT | Shard keyspace, sub-partition, or hierarchical budget |
| Check budget | Sub-ms p99 on gateway | Redis RTT + serialization dominates; pool connections |
Implications: You cannot afford a full distributed consensus round per request. You pipeline, Lua-batch multi-window checks, and isolate abusive keys before they starve the cluster.
If you remember one thing: Sub-ms budget means O(1) key ops—not consensus per request.
High-level architecture
Treat the limiter as a data-plane service on the request path and a control-plane for policies. Edge / API gateway receives traffic, runs authentication (to know user_id or api_key), then calls the limiter with a normalized key (e.g. tenant:route:user). The limiter executes atomic logic against a low-latency store (most interviews: Redis Cluster). Config service or feature flags push limit definitions (tokens/minute, burst, whitelist). Observability (metrics, tracing) records check latency and decisions—otherwise you fly blind when Redis slows down.
Who owns what:
- API gateway — TLS, routing, authn, first-line abuse signals, invokes limiter before expensive backend work.
- Rate limiter service (optional thin layer) — Encapsulates key derivation, policy lookup, Lua scripts, and header formatting so gateways stay dumb and fast.
- Redis / shared store — Authoritative counters; sharded by hash(key); optional replica reads only if you accept stale reads (many designs use primary for correctness).
- Control plane — Policy CRUD, canary rollouts, emergency global throttle.
Async work is minimal on the hot path: policy sync can be cached in-process with TTL. Optional async analytics (log sampled blocks to Kafka) must not block allow/deny.
[ Client ]
→ [ LB ] → [ API Gateway ]
|
| sync: derive key, check quota
v
[ Rate limiter lib ] ──atomic──► [ Redis Cluster ]
| (counters + TTL)
| allow / deny
v
[ Upstream services ]
Control plane (async): [ Policy store ] ──► gateway cache (TTL refresh)
In the room: Narrate one request end-to-end: key string, single RTT (or Lua), 200 vs 429, headers. Then say what happens when Redis is slow (timeout → fail-open vs closed).
If you remember one thing: Gateway checks before expensive upstream work; Redis is authoritative for global counts.
Core design approaches
Fixed window
Partition time into buckets (e.g. minute boundaries). INCR per bucket key, EXPIRE after window. Cheapest; worst at edges—two windows back-to-back can allow 2N requests in a short span.
Sliding window (exact or approximate)
Track events in a sliding interval—sorted sets, ring of sub-buckets, or Redis recipes with bounded error. Fairer; more CPU/memory per key.
Token bucket
Refill tokens at rate r, bucket capacity B. Smooth bursts; maps well to product language (“burst then steady”). Implement with last refill timestamp + atomic read-modify in Lua.
When to pick: Fixed window for coarse abuse caps; token bucket for API products that promise bursts; sliding window when fairness at the minute boundary is a support ticket magnet.
If you remember one thing: Pick the algorithm for burst shape and Redis cost—not because it sounds fancy.
Detailed design
Read path (every HTTP request)
- Gateway authenticates and builds limit key (
tier:route:principal). - Limiter loads policy from local cache (versioned); miss → fetch control plane (rare).
- Atomic check-and-update in store (Lua or INCR pipeline).
- If allowed → attach X-RateLimit-* headers; forward upstream.
- If denied → return 429 + Retry-After; do not call upstream (save cost).
Write path (policy / admin)
Policy changes are eventually visible at gateways (seconds). Critical emergency kill switch can push via config channel or DNS/feature flag—not every design needs instant global policy sync for interviews.
Idempotency and charging
Clarify whether retries of the same logical operation consume quota twice. Strong answers use Idempotency-Key for writes and may exclude duplicate retries from counting when the backend dedupes.
If you remember one thing: 429 should not call upstream—save money and protect backends.
Key challenges
- Correctness vs cost: Exact sliding windows at 10M checks/s per cluster may require approximation; admit error bounds.
- Hot keys: One
client_idmaps to one Redis slot—CPU and network collapse there; mitigation is part of the design, not an afterthought. - Layered limits: Per-user + per-IP + global must compose without N sequential RTTs—Lua or batched keys.
- Clocks: Windows are usually server-based; clients sending
Retry-Aftermust not trust client clocks for enforcement. - Multi-tenant fairness: Noisy neighbor on shared Redis can raise everyone’s p99—quotas, isolation by tenant prefix, or dedicated clusters for large customers.
If you remember one thing: Hot keys and layered limits are design requirements—not production surprises.
Scaling the system
- Shard Redis by hash(key); ensure related policies share patterns that don’t create hotspots (salting rarely needed if keys are already high-cardinality).
- Horizontal gateways scale statelessly; Redis scales out (cluster) until ops cost hurts—then dedicated limiter tier with batching.
- Regional limits: stale cross-region counts are acceptable for many products; global strict caps may need central authority or sticky routing—say latency vs accuracy.
- Read replicas for limiter state are risky for correctness—prefer primary for increments unless you explicitly design probabilistic local caches.
If you remember one thing: Gateways scale statelessly; Redis scales until you need sharding and abuse isolation.
Failure handling
| Scenario | Bad outcome | Mitigation |
|---|---|---|
| Redis timeout | Unbounded traffic (fail open) or outage (fail closed) | Circuit breaker; cached last decision for microseconds; policy per route |
| Redis failover | Counter reset → temporary over-allow | Accept burst; lower limits briefly; monitor anomaly |
| Gateway deploy | Mixed policy versions | Version keys; graceful cache warm |
| Thundering herd after 429 | Clients ignore Retry-After | Jitter in Retry-After; exponential backoff docs |
Degraded UX: Users see more 429s or slower responses; outage is when gateways error without policy—avoid that for auth paths.
If you remember one thing: Fail-open vs fail-closed is a product/security choice—never “we’ll decide later.”
API design
Rate limiting is usually not a standalone public REST product in the interview—it is behavior on existing APIs. Still, spell out how clients observe limits.
Gateway-injected headers (common pattern):
| Header | Role |
|---|---|
X-RateLimit-Limit | Max requests per window for this policy |
X-RateLimit-Remaining | Decrements on success; can be approximate |
X-RateLimit-Reset | Unix time when window resets |
Retry-After | Seconds (or HTTP-date) when returning 429 |
429 response body: Machine-readable code, human message, optional retry_after_ms—helps mobile clients.
Internal admin API (sketch):
GET /v1/admin/policies/{id}
PUT /v1/admin/policies/{id} # burst, rps, scope
POST /v1/admin/overrides # temporary whitelist / blocklist
Request flow (hottest read):
GET /v1/resource
→ Gateway: auth → limiter.Check(key) → Redis Lua
→ 200 + X-RateLimit-* → upstream
→ 429 + Retry-After (stop)
Errors: 401 before limiter if unauthenticated; 429 for throttle; 503 if upstream overloaded—distinct from throttle so clients don’t backoff incorrectly.
If you remember one thing: Retry-After on 429 is part of the API contract—not optional polish.
Production angles
Rate limiting is economics and physics: you buy fairness and survival with Redis round-trips, Lua CPU, and user trust when 429s hit real traffic. The interesting failures are not “too many 429s”—they are hot keys with flat 429 graphs, policy deploys that silently shift quotas, and gateways queuing while Redis looks green because slow is not down.
Redis CPU pegged, 429 mix looks “normal”
What users saw — APIs feel slow; checkout times out; 429 rate barely moves—users blame “the app,” not “rate limited.”
Why — One hot key hammers a single Redis slot. Lua does too much work per check. Redis is fast until one key serializes every request.
What good teams do — Shard counters (user:123:shard:k); probabilistic structures when exactness is optional; isolate worst tenants on dedicated Redis. Profile Lua like app code.
Legitimate users throttled right after a deploy
What users saw — Support spike: login and checkout 429 right after a release; rollback fixes it.
Why — Mixed limiter versions during deploy; failover resets counters; feature flag tightened defaults without canary.
What good teams do — Canary policies per route; watch X-RateLimit-Remaining distribution; synthetic probes on critical keys post-deploy.
Gateway queues grow while Redis “healthy”
What users saw — p99 through gateway jumps; thread pools full; 503 before many 429s.
Why — Synchronous Check on every request; starved connection pool to Redis; one tenant fills the pool.
What good teams do — SLO on limiter.check p99 separate from origin; bulkheads per tier; alert blocked connections, not only Redis CPU average.
[ Spike traffic ] → [ Gateway queue ] → [ Limiter: Redis slow ]
|
p99 latency ↑
still 200 until queue drops or timeout → 503
How to use this in an interview — Pick hot key or gateway queue behind slow Redis. Name one metric (limiter.check p99, top key QPS) and one mitigation. State fail-closed on login, fail-open on catalog if asked.
Bottlenecks and tradeoffs
Exactness vs throughput
The tension — Sliding windows feel fair; exact structures cost more Redis work per check.
What breaks — p99 for Check blows the sub-ms budget at 10M checks/s.
What teams do — Approximate sliding windows; token bucket with Lua refill; admit small error bounds.
Say in the interview — Name fairness vs Redis CPU—not “we use sliding window” alone.
Central store vs edge pre-check
The tension — Edge-only is fast; global caps need a remote round trip.
What breaks — Pure edge under-enforces; pure central adds RTT.
What teams do — Hierarchical: local hard cap + Redis global refine in one Lua pipeline.
Say in the interview — Draw two layers when they ask about 50 gateways.
Availability vs abuse on failure
The tension — Fail-open keeps revenue flowing; fail-closed stops credential stuffing when Redis blips.
What breaks — Wrong default on login during Redis outage = security incident.
What teams do — Route-level policy; circuit breaker with short cached decision only where safe.
Say in the interview — “Catalog read fail-open; login fail-closed”—and mean it.
If you remember one thing: The limiter can become the bottleneck that protects nothing if Redis or the gateway queue is ignored.
What should stick
You do not need every Redis command. You should leave knowing:
- Shared state — Global limits need one authoritative counter per key (or honest hierarchy).
- Algorithm choice — Fixed window is cheap but spiky; token bucket for product bursts; sliding for boundary fairness.
- Atomicity — INCR+EXPIRE or Lua for read-modify-write in one RTT; pipeline layered checks.
- HTTP contract — 429 +
Retry-After+ limit headers; distinct from 503. - Failure is policy — Fail-open vs fail-closed per route; hot keys need sharding.
Tell it in the room: “Every request: gateway builds tier:route:principal, Lua atomic check in Redis, 200 with headers or 429 with Retry-After without calling upstream. Token bucket for burst. Login fails closed if Redis times out; catalog may fail open with a tight local shadow cap. One hot client_id → shard the counter key.”
Reference diagram
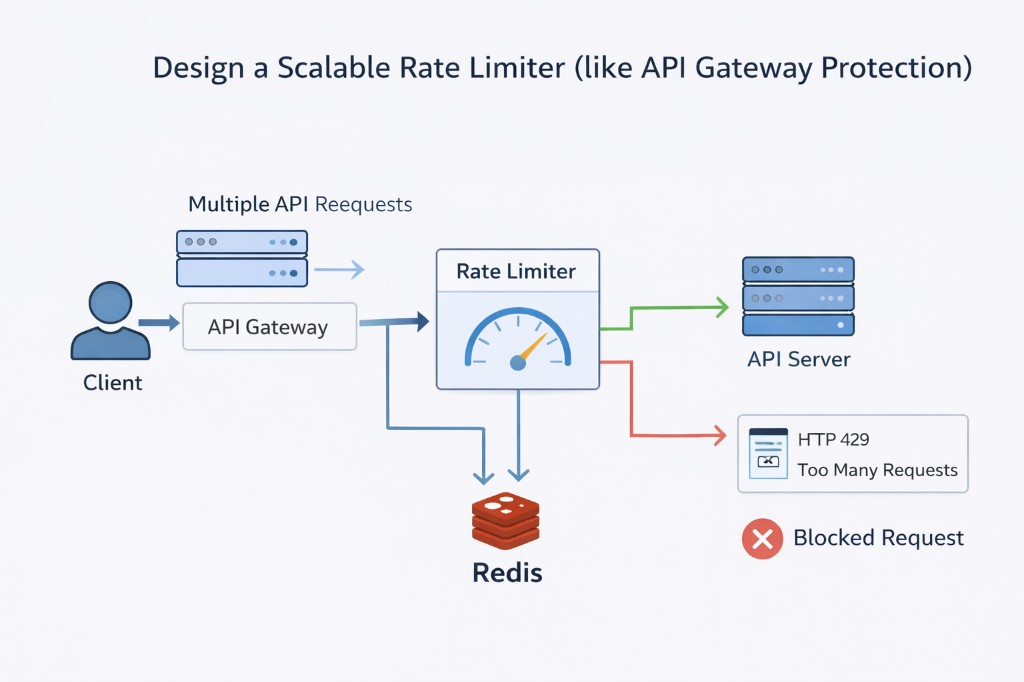
What interviewers expect
- Clarify dimensions first: limit by user id, API key, IP, route, or composite key; define burst (token bucket) vs rigid window semantics before you pick Redis data structures.
- Name at least one algorithm and its failure mode: fixed window (cheap, boundary spikes), sliding window (fairer, more work), token/leaky bucket (smooth bursts, product-friendly).
- Distributed state: where counters live (Redis cluster, dedicated limiter service), atomicity (INCR+EXPIRE, Lua, CAS loops), and why “each gateway counts locally” is wrong for global caps.
- Latency story: budget for check (e.g. under 1 ms p99); optional local pre-check + remote refine; pipelining and connection pools.
- HTTP contract: 429, Retry-After, X-RateLimit-Limit / Remaining / Reset (or vendor equivalents); idempotency of POST vs charging GET—state your product rule.
- Hot keys: one OAuth client or NAT IP; mitigation (sub-keys, hierarchical budgets, regional caps).
- Failure: fail-open (availability, abuse risk) vs fail-closed (security); circuit breakers; stale allowance—justify for login vs public read API.
- Observability: limiter check latency, Redis error rate, top blocked keys, not just 429 count.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Token bucket vs sliding window—when do you pick each?
- How do you implement distributed rate limiting without crushing Redis?
- What happens when two gateway nodes race on the same key?
- How do you handle a hot key for one abusive client?
- Fail open or fail closed—what do you choose for an API vs a login endpoint?
Deep-dive questions and strong answer outlines
How does a token bucket work for HTTP APIs?
Tokens refill at a steady rate; each request consumes one (or weighted). Allows smooth bursts up to bucket capacity. Contrast with fixed window where a client can spike at window boundaries.
Where do you store counters at 10M checks/s?
In-memory per process is wrong for global limits. Use a fast remote store (often Redis) with sharding by key, pipelining, and TTL aligned to windows. Mention hot-key mitigation (sub-keys, regional budgets) if pushed.
How do you make increments correct under concurrency?
Single-key atomic ops: INCR + EXPIRE, or Lua script for check-and-set in one round trip. For sliding windows, use sorted sets or approximate structures (Redis sliding window algorithms) and admit error bounds if they ask for scale.
What do you return when limited?
HTTP 429, meaningful body, Retry-After seconds or timestamp, optional X-RateLimit-Remaining and reset time. Helps clients backoff without hammering.
How do layered limits (per user + per IP + global) compose?
Check innermost budget first for cheap rejection, then outer caps—often implemented as nested keys or pipeline of checks in one Redis round trip with Lua. Define precedence when budgets disagree (e.g. authenticated user id beats IP for fairness).
How do you test rate limits without flaky tests?
Deterministic clock injection for windows, unit tests on pure counter math, and integration tests with controlled Redis or embedded fake with same semantics—not wall-clock sleeps in CI.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Do I need exact counts or is approximate OK?
A: Many production systems accept small error (e.g. sliding window approximations) for massive scale. Say the tradeoff: exact Lua scripts vs cardinality structures vs local leakage.
Q: Is Redis always the answer?
A: Often, because of atomic ops and TTL. Alternatives: dedicated limiter service, edge SDK with sync, or hierarchical limits (local allow list + global Redis). Show you know why you picked one.
Q: How is this different from a queue?
A: Rate limiting rejects or delays excess traffic; queues buffer work. You may combine (e.g. 429 vs 503 with queue upstream), but the interview question is usually synchronous allow/deny.
Q: How do I talk about global vs per-region limits?
A: Eventually consistent cross-region counts are hard. Options: sticky routing, regional budgets, or central authority for strict global caps—name consistency vs latency.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.