System design interview guide
Facebook Post Search System Design
User searches their timeline for "beach wedding 2019" across posts with photos, links, and privacy scopes—global search must never return friends-only posts to strangers. Per-user index shard + privacy filter on every query is the trap.
Problem statement
Privacy-aware search over social posts at scale.
Introduction
You type a friend's name after a party. Two posts match. One is a public photo. The other is friends-only from someone you are not connected to.
If your design returns both and filters later in app code, you just leaked a private post—or you burned seconds scanning millions of doc ids.
Social search is find the words plus who is allowed to see this. The interview tests whether you know posting lists are not enough. You must prune candidates using visibility rules without blowing the latency budget.
Weak answers index full text and filter millions of hits in application code. Strong answers constrain retrieval with visibility metadata in the index, precomputed audience keys, or two-phase retrieval with a bounded candidate set.
If you remember one thing: Search hits are useless until they pass ACL—treat privacy as part of retrieval, not a footnote.
How to approach
Talk like you are walking through one search request, not listing Lucene buzzwords.
- Ask scope — Public web-style search or network-only? Filters (author, time, type)? Autocomplete in scope?
- Capacity sketch — Billions of docs, high QPS, freshness in seconds to minutes—what does that forbid?
- One query path — Parse → shard fan-out → merge top-k → ACL filter → rank → return with cursor.
- One index path — Post event → tokenize → update posting lists → NRT segment → async merge.
- Name the expensive join — Where does graph / ACL run, and what is your timeout if it is slow?
In the room: "I'll clarify search scope, walk one keyword query through shards and ACL, then describe how new posts enter the index asynchronously."
If you remember one thing: Draw query fan-out and ACL on the same diagram—interviewers push on that join.
Interview tips
Five common back-and-forths. Each block: a trap answer, a follow-up, and where to land.
Filtering after retrieval
You: "We run the query, get all matches, then filter by privacy in the app."
They ask: "A hot term matches ten million posts—how long does that filter take?"
Land here: Use two-phase retrieval: cheap posting list intersection for a bounded top-N, then batch ACL checks. Or index visibility facets so the filter is a cheap bitmask step—not a graph call per hit.
Sharding the inverted index
You: "We shard by term so queries are fast."
They ask: "What happens when someone publishes a long post with many unique words?"
Land here: Term sharding makes writes touch many shards. Doc sharding keeps writes local but fans out every query. Pick doc sharding at hyperscale; name aggregator merge cost and per-shard timeouts.
Index freshness
You: "The index updates in real time."
They ask: "A harmful post is deleted from the feed but still appears in search for two minutes—what do you tell legal?"
Land here: NRT is eventually consistent. State a freshness SLA in seconds. Add a tombstone layer at query time for safety deletes so search can block doc ids even when the index lags.
Hot terms and celebrity spikes
You: "Inverted indexes handle any query the same way."
They ask: "Everyone searches the same viral hashtag—what happens to p99?"
Land here: Posting lists for hot terms are huge. Cap candidate pools, use WAND-style pruning where supported, cache head queries with short TTL (careful with personalization), and rate limit abusive patterns.
Pagination
You: "We use offset pagination like page 2, page 3."
They ask: "Scores change while the user scrolls—do they see duplicates or skips?"
Land here: Use an opaque cursor tied to a snapshot or stable sort key. Be honest: changing scores mean dup/skip unless you freeze rank for that session—same tension as feeds.
If you remember one thing: After each push, name one mechanism—bounded candidates, tombstone layer, doc sharding—not "we'll optimize later."
Capacity estimation
Rough numbers stop you from treating search like a SQL LIKE on a single table.
| Axis | Rough scale | What it means for design |
|---|---|---|
| Corpus | Billions of posts | Shard by doc_id (common) or term (query-local, write-heavy) |
| Query QPS | High read volume | Aggregator becomes the bottleneck; cache head queries carefully |
| Freshness | NRT often seconds–minutes | Smaller segments = fresher index, heavier merge load |
| Long tail | Most queries are rare | Cache helps head terms; tail needs bounded work per request |
So we cannot: pull unbounded posting lists for common terms and ACL-filter afterward. We cannot promise zero staleness at web scale without qualifiers. We cannot cache personalized results like generic top queries.
If you remember one thing: Fan-out to N shards plus ACL batch must fit inside your p95 budget—math first, boxes second.
High-level architecture
What breaks if you grep the database
Running LIKE across a posts table fails on billions of rows. Even a read replica will melt on head terms. Privacy rules tied to the social graph make row scans worse—you need an index built for term lookup, not table scan.
What works: index plus query orchestration
When someone writes a post, the post service emits an event. An indexer tokenizes text and updates inverted indices (Lucene-class engines or managed OpenSearch). When someone searches, a query service parses the request, fans out to index shards in parallel, merges top-k per shard, applies ACL with viewer context, ranks, and returns a page.
Who does what:
- Index clusters — Sharding, replication, segment merges, NRT refresh.
- Aggregator / query service — Scatter-gather, global merge, timeouts, partial-result policy.
- Graph / ACL service — Friend lists, block sets, custom audiences for the filter phase.
- Post service — Source of truth for content; emits create/update/delete events.
[ Post write ] --> event bus --> Indexer --> Index shards (inverted lists)
[ Search request ]
--> Query svc --> parse + plan
--> shard1, shard2, ... shardN (parallel top-k)
--> merge candidates
--> ACL filter (viewer context)
--> rank + truncate --> response
In the room: Narrate whether ACL runs before rank (cheap facets) or after retrieval (batch graph checks)—and say which costs more for this product.
If you remember one thing: Write path is async; read path is fan-out + merge + ACL—two different performance stories.
Core design approaches
Shard by doc id vs shard by term
Doc-based shards: Each shard owns a range of doc ids. Writes stay local. Every query fans out to all shards (or a pruned subset) and merges top-k.
Term-based shards: Each shard owns hot terms. Queries hit fewer shards. Every new post updates posting lists on many shards—writes get expensive.
Most hyperscale social search picks doc sharding and invests in a fast aggregator.
If you remember one thing: Sharding picks whether writes or queries pay the coordination tax—say which you chose.
Visibility in the index
Store a visibility enum in the doc metadata: public, friends, custom audience id.
At query time, filter with the viewer's friend list, block set, or precomputed ACL bitmap.
Precomputed per-viewer bitmaps work for small audiences. They do not scale to every user pair on the planet.
Alternative: retrieve top-N text matches, then batch graph checks—bound N hard.
If you remember one thing: ACL is either indexed metadata (cheap filter) or graph calls (accurate, slow)—hybrids are common.
Detailed design
Walk one search and one new post step by step.
Indexing path
- Event
PostCreatedarrives with text, author, timestamp, visibility, language. - Tokenizer maps text to term ids; append doc id to each term's posting list; store forward index for snippets.
- New segment becomes searchable (NRT); background merge compacts segments.
PostDeletedor visibility change emits tombstone or update event—doc id must drop from results within your SLA.
If you remember one thing: Deletes and privacy changes are events, not afterthoughts—lag here becomes a trust incident.
Query path
- Parse query string; optional spellcheck; apply filters (author, time window, post type).
- Fetch posting lists; intersect terms; score with BM25 plus recency and social boosts.
- Take top N candidates (bounded); filter ACL via graph service batch or indexed facets.
- Re-rank if needed; return results plus opaque cursor for pagination.
In the room: Say your N cap out loud—"we never graph-check more than 500 candidates."
If you remember one thing: Bounded candidates protect you when a term's posting list is the size of a city.
Key challenges
For each item, say what the user or trust team sees if you get it wrong.
- Fan-out latency — Many shards in parallel; one slow shard ruins p99. Timeout per shard; define partial vs fail policy.
- ACL cost — Batch graph checks; cache friend lists with short TTL; stale cache can leak or hide—pick your poison.
- Freshness vs write load — Smaller segments refresh faster; merges steal CPU and delay everything.
- Spam and query abuse — Downrank or drop spam at index ingest; rate limit queries by user and IP.
- Pagination under changing scores — Cursors help; admit dup/skip when rank moves—same as feeds.
If you remember one thing: p99 on head terms and stale deletes are the stories interviewers expect from prod—not inverted index definitions.
Scaling the system
- Horizontal index nodes with replicas for read QPS; watch uneven doc distribution creating hot shards.
- Cache popular queries with short TTL—personalization breaks naive caching.
- Regional indices when latency or data residency requires federated query across regions.
- Tiered indexing for celebrity authors or safety-critical content—fresher segments, dedicated pipeline.
If you remember one thing: Scale the aggregator and ACL batch path—not only leaf index shards.
Failure handling
| What happens | What user sees | What to build |
|---|---|---|
| One shard slow | Empty or thin results | Per-shard timeout; omit shard (best-effort) or retry once |
| Graph / ACL slow | Long spinner or error | Timeout ACL; return public-only degraded mode if product allows |
| Indexer lag | Stale or missing hits | Alert on lag; tombstone layer for deletes; tier hot authors |
| Query flood | 429 or shed | Rate limits; blocklist expensive patterns |
Real outage = wrong posts visible (ACL bug) or search down entirely. Partial shard loss should not return private content.
If you remember one thing: Degraded search should fail closed on privacy, not fail open.
API design
Main surface for clients:
| Endpoint | Role |
|---|---|
GET /v1/search | Keyword search with filters and pagination |
GET /v1/search query params:
| Param | Role |
|---|---|
q | Query string |
cursor | Opaque pagination token |
limit | Page size (server cap) |
author_id | Filter by author |
since, until | Time window |
type | Post type (text, link, photo) |
Diagram (read hot path):
Client --> API GW --> Search svc --> index shards --> merge top-k
|
ACL svc (batch)
|
rank + cursor --> response
Errors: 429 query flood; 400 malformed query. Do not leak whether a private post existed—return empty or generic errors per product policy.
In the room: Walk GET /v1/search from gateway to shard merge to ACL batch in under a minute.
If you remember one thing: The hottest read is search—every param should bound work (limit, time window, candidate cap).
Production angles
Search behind a social graph is not "Elasticsearch plus ACL." Posting lists can be enormous. ACL fan-out can dwarf retrieval. Near-real-time indexing is never quite fast enough for safety or legal.
p99 explodes on "cheap" queries and common terms
What users saw
Search felt slow or timed out when everyone queried the same celebrity name or viral hashtag.
Median latency looked fine. Support tickets clustered around trending queries, not index outages.
Why
High-frequency terms have massive posting lists. If you union too many doc ids before ACL trims them, you move megabytes per request.
Stopwords do not save you—hashtags, mentions, and numeric spikes behave like stopwords during news events.
What good teams do
Two-phase retrieval with a hard candidate cap. WAND-style max-score pruning where the stack supports it.
Per-shard latency histograms—not only global p99. Cache head queries with short TTL; invalidate on trends.
Blocklists and query rewriting for abusive patterns.
Indexed doc says "live" but the post was deleted or moderated
What users saw
A harmful post disappeared from the feed but still appeared in search snippets for minutes.
Legal and trust teams escalated. Dashboards showed index lag of "only" 60 seconds—which felt like forever.
Why
NRT is eventually consistent. Delete and visibility updates may lag behind the feed path.
Denormalized visibility facets may not invalidate instantly when ACL changes.
What good teams do
Tiered SLAs: sub-minute for safety verticals.
Tombstone layer at query time blocks known-deleted doc ids even when segments lag.
Negative cache of deleted ids in a fast store. Name which service owns truth (moderation vs index).
Merge-tier overload during news spikes
What users saw
503s or timeouts from search even though individual shards looked healthy.
Empty result sets spiked—users thought search was "censoring" when the system was shedding load.
Why
Fan-out to many shards is O(shards) coordination. ACL batch calls add RTT and head-of-line blocking.
A push notification can trigger a thundering herd of identical queries.
What good teams do
Request budgets per query phase. Early termination when score upper bounds cannot beat current top-k.
Request coalescing for identical queries in the aggregator.
Measure shard latency histogram, index lag, ACL batch p95, and empty result rate.
[ Query spike ] --> aggregator thread pool full --> 503 or shed
How to use this in an interview — Lead with posting list size + ACL, not inverted index 101. Pick one failure: stale delete, hot term, or aggregator saturation. Name one metric (p99 per shard, index lag) and one mitigation (tombstone layer, candidate cap).
Bottlenecks and tradeoffs
Exact ACL vs latency
The tension — Strong privacy requires accurate graph checks; accuracy adds round trips.
What breaks — p99 latency when ACL service slows; or leaks when you cache friend lists too aggressively.
What teams do — Indexed visibility facets for the common case; batch graph checks for edge cases; short TTL caches with clear stale behavior.
Say in the interview — "We filter with facets first, graph-batch only the top 500 candidates."
Personalization vs cache
The tension — Head queries cache well; personalized ranking breaks shared cache keys.
What breaks — Cache hit rate drops; cost rises on the tail.
What teams do — Cache generic browse queries separately from logged-in personalized search; shorter TTL on personalized paths.
Say in the interview — Name what you cache and what you never cache.
If you remember one thing: Social search tradeoffs are ACL accuracy, freshness, and hot term size—not index brand choice.
What should stick
You do not need to memorize every box. After this guide, you should be able to:
- Retrieval + ACL — Posting lists find words; visibility decides what the searcher may see.
- Doc sharding + fan-out — Writes local; queries scatter-gather and merge top-k with timeouts.
- Bounded candidates — Never ACL-filter unbounded posting lists for hot terms.
- NRT with a SLA — Index lag is product policy; tombstones protect safety when segments lag.
- Head term p99 — Median latency hides celebrity-query pain—watch per-shard tails.
Tell it in the room: "Posts emit async index events. Search fans out to doc shards, merges top-k, batch-checks ACL with a hard cap, ranks, and returns a cursor. Deletes tombstone doc ids; safety paths can block ids at query time even if the index lags. Hot terms need candidate caps—not bigger clusters alone."
Reference diagram
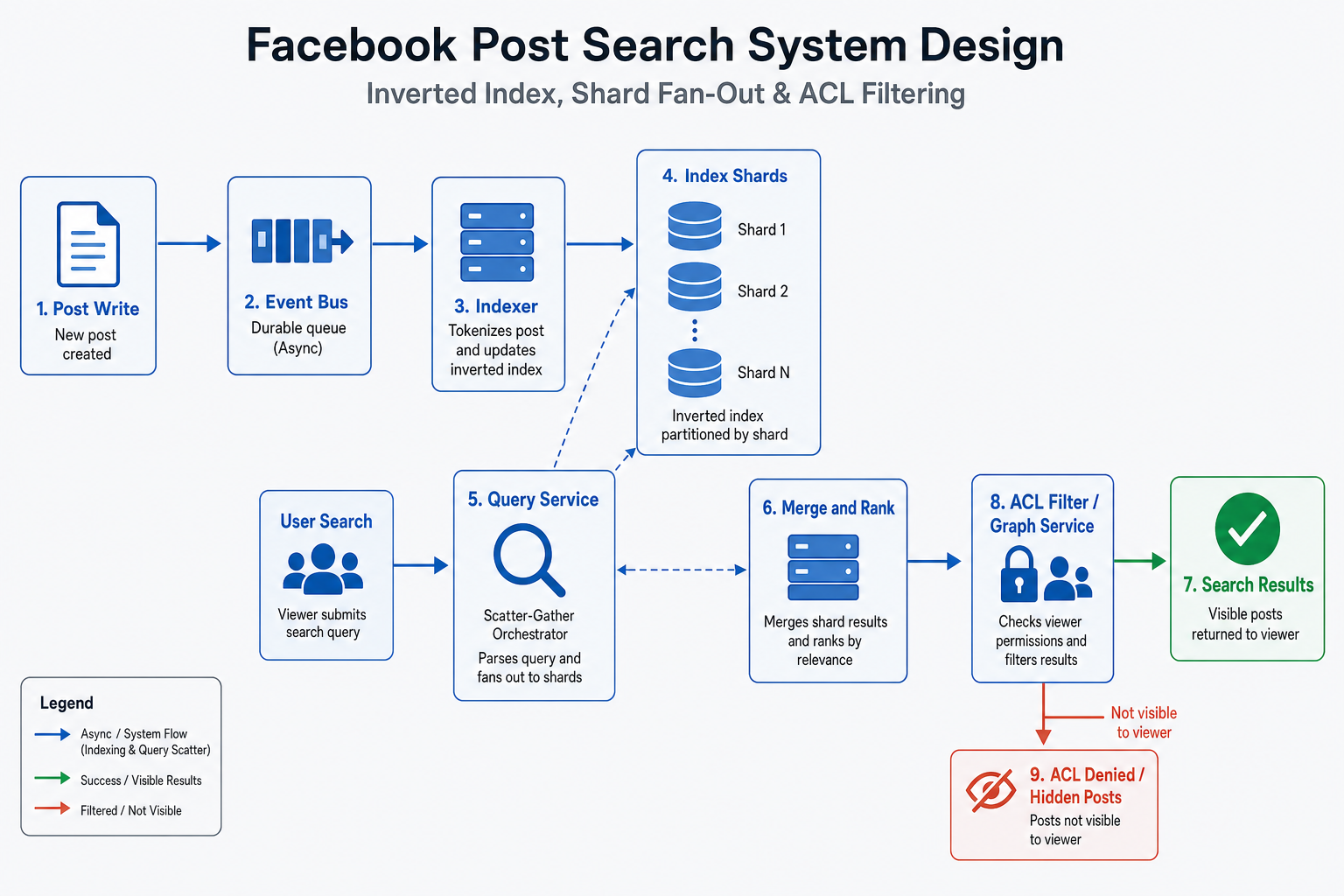
What interviewers expect
Inverted index with visibility field; filter post-query; incremental pipeline.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Privacy enforced how?
- Shard index?
- Real-time index?
- Search photos?
- Delete post?
Deep-dive questions and strong answer outlines
Privacy?
Index visibility enum (public/friends/self); query includes viewer_id filter; graph check for friends.
Index update?
Post create event → tokenizer → shard by author_id or global with ACL field.
Query?
Scatter to shards → merge top-K → authorize each doc against viewer.
Delete?
Tombstone doc id in index; compact segments async.
Media text?
Async OCR pipeline enriches index—off write path.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Graph search?
A: Different from post content search—clarify scope.
Q: Elasticsearch?
A: Pattern ok; privacy filter still required.
Q: Personalization?
A: Boost friends posts after safety filter.
Q: Hashtags?
A: Separate token field in index.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.