System design interview guide
Nearby Friends System Design
Friend map updates every 30 seconds for 10M users in a city—naive "query all friends distance" is O(n) per pan. Geospatial index + privacy grid + push diffs keep the feature usable without draining batteries.
Problem statement
Nearby friends: location updates, geospatial queries on friend graph, privacy.
Introduction
You open the app at a festival. “Three friends nearby.” One dot is your roommate—still shown at the venue though they left an hour ago. Another friend never opted in but appears on a leaked screenshot. Legal asks why you stored exact GPS for six months.
That is what users feel. The interview is half spatial indexing and half privacy.
Weak answers compute distance to every friend on every request—O(n) Haversine against a global user table. Strong answers reduce the candidate set using grid cells (geohash, S2, quadtree), then intersect with the friend graph, then refine distance for a small set.
Interviewers dock you if you store precise coordinates forever, ignore opt-in, or forget hot cells (concerts, stadiums).
If you remember one thing: Spatial prune first, graph filter second, privacy rules always—not Haversine in a loop over all friends.
How to approach
Walk one “who is near me?” query—not “we use Redis geo.”
Confirm precision (neighborhood vs exact), who is in the graph, and update policy (how often GPS fires). Sketch write path (quantize → index) and read path (cells → candidates → filter → rank). Privacy and TTL are not footnotes—they shape storage.
In the room: “I’ll confirm opt-in and display precision, then walk location write and nearby read before hot cells and abuse.”
If you remember one thing: Write path throttles and quantizes; read path shrinks candidates before graph intersect.
Interview tips
Five exchanges that separate geo trivia from a shippable design.
Geohash / S2 cells
You: “We store lat/long in Postgres and query distance.”
They ask: “Five hundred million users—do you scan everyone within 500m?”
Land here: Map lat/lon to cell id at chosen resolution. Nearby = union of neighboring cells. Prefix queries in KV—not pairwise distance on the whole user table.
TTL and retention
You: “We keep location history for analytics.”
They ask: “User opts out—what do you delete and when?”
Land here: Raw location blobs expire (e.g. 24h) unless refreshed. Opt-out deletes index rows. Display uses coarse buckets—not exact meters unless product insists.
Frozen / hidden mode
You: “User toggles privacy off.”
They ask: “Does their phone still send GPS in the background?”
Land here: Freeze is a state machine: stop writes, reads return last known or hidden. Not a boolean flag on one field.
Friend count at P99
You: “Intersect candidates with friends in memory.”
They ask: “Power user with five thousand friends at a stadium?”
Land here: Median friend count is small—in-memory intersect is fine. At P99 thousands, mention precomputed friend sets, Bloom filters, or cap intersection work—if pressed.
VPN and mock GPS
You: “Show whatever the device sends.”
They ask: “User teleports from NYC to London in one ping?”
Land here: Degrade gracefully—“location unknown” or ignore outlier jumps. Optional device accuracy and mock-location signals.
If you remember one thing: Name cell, TTL, opt-in, intersect, coarse display—not “PostGIS.”
Capacity estimation
| Load | Note |
|---|---|
| Location writes | Can exceed read QPS if unthrottled—sample and quantize |
| Index | Cell → set of user ids or user → cell—choose based on query vs update pattern |
| Friends per user | Median small; P99 still matters for algorithm choice |
| Hot cells | Stadium → write and read spike on same shard |
Implications: Batch writes; regional partition of spatial index; rate limit per device.
If you remember one thing: Unthrottled GPS writes can exceed read QPS—quantize and sample on the client first.
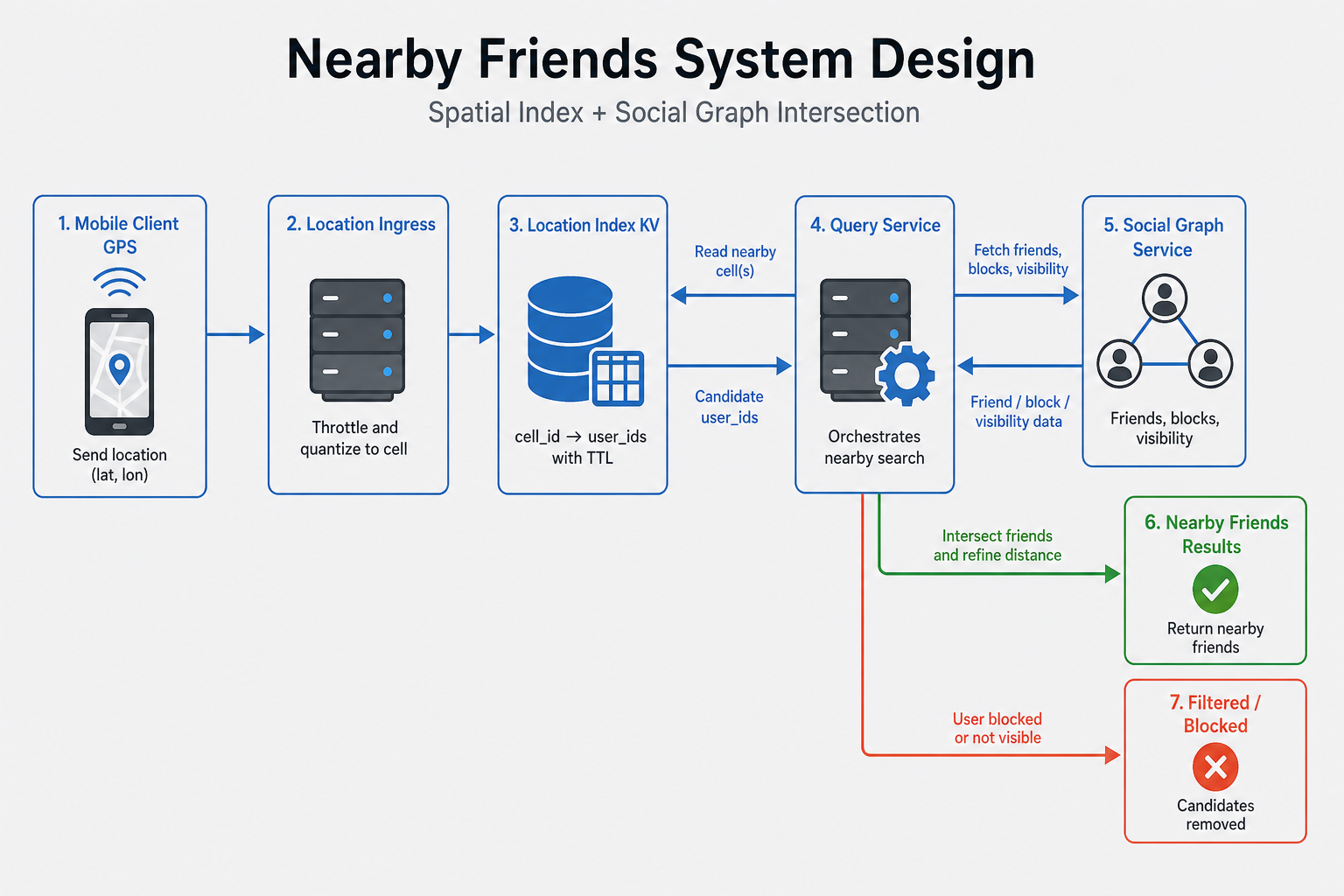
High-level architecture
Location ingress receives quantized updates (only when cell changes or min interval elapsed). Location service stores user_id → cell_id, coarse_lat, coarse_lng, updated_at with TTL. Social graph service returns friend ids (with permission). Query service runs nearby for viewer: compute cells covering radius → lookup candidates in spatial index → intersect with allowed friend set → Haversine refine → rank.
Who owns what:
- Graph service — Friend edges, blocks, visibility lists (who can see me).
- Location index — Short TTL PII; sharded by region or cell prefix.
- Query API — Orchestrates; enforces blocks on result set.
[ Client GPS ] --throttle--> [ Location ingress ]
|
quantize to cell_id, TTL
v
[ Location index KV ]
(cell_id -> user_ids) OR (user_id -> cell_id)
[ Query: nearby friends for viewer V ]
1) Graph: friend_ids + visibility
2) V's position -> cells covering R
3) Index: candidate user_ids in those cells
4) candidates ∩ friends ∩ not blocked
5) refine distance, rank, return coarse distance + last_updated
In the room: Say why step 4 is small—spatial pruning before graph, not after scanning all friends.
If you remember one thing: Query = cells → candidates → ∩ friends → refine distance for survivors only.
Core design approaches
Indexing pattern A: user → cell
Write: O(1) update user_id → cell. Read: Union all friend cells’ neighbors—works if friends are few; worse if many friends spread globally.
Indexing pattern B: cell → users (posting lists)
Write: Add user to cell set (or geohash prefix structure). Read: Scan cells in radius → candidates → intersect friends—better when radius is small vs global user density.
Hybrid: Store user→cell for latest; maintain reverse index for query—choose tradeoff for hot cells.
Privacy
Display rounded distance buckets (“within 500m”) not exact meters unless product insists. Coarser cell in rural areas may need dynamic resolution—S2 levels help.
If you remember one thing: Cell → users posting lists win for small-radius queries; user → cell helps writes—pick hybrid if hot cells hurt.
Detailed design
Write path (location update)
- Client obtains GPS; drops if accuracy poor or frozen.
- Client maps to cell at level L; if same as last sent and time not elapsed, skip network.
- Server upserts
user_idlocation row; updates cell index atomically (or async with eventual consistency + honest stale UI).
Read path (nearby friends)
- Auth viewer; verify opt-in and not hidden.
- Load friend ids from graph (cached).
- Map viewer position to cells for radius R (may be ring of cells).
- Fetch candidate user ids from spatial structure per cell (merge dedupe).
- Filter
candidates ∩ friends; exclude blocked; drop stale beyond TTL. - Compute distance for survivors; sort by distance + recency + affinity weights.
In the room: Write only on cell change or min interval; read never scans all friends—only cell candidates intersected with graph.
If you remember one thing: Throttle writes; intersect a small candidate set; show last updated in UI.
Key challenges
- Write amplification: Raw GPS at 1 Hz × DAU = unsustainable—quantize, event-based updates.
- Hot cells: Millions of users in one cell—shard by subcell or cap result size; precompute nothing global.
- Stale vs creepy: Showing friend “nearby” when they left 30 min ago—show last updated in UI; expire old dots.
- Graph churn: Unfriend / block must reflect quickly on query path—cache friend lists with short TTL.
- Cross-region: Friends traveling—location region may differ from graph region—federated query or central index with latency cost.
If you remember one thing: Write amplification, hot cells, stale dots, and graph churn are the named user-visible risks.
Scaling the system
- Partition location data by geographic region (rough) or cell prefix—locality of writes.
- Cache friend lists at edge with invalidation on social events.
- Read replicas for graph; primary for location writes in hot regions.
- Rate limit query API to prevent stalking enumeration (scanning grid).
If you remember one thing: Partition location by region/cell prefix; cache friend lists with short TTL and invalidate on block/unfriend.
Failure handling
| Scenario | Degraded UX | Mitigation |
|---|---|---|
| Stale index | Wrong nearby set briefly | TTL + version; client refresh |
| Graph service slow | Slow query | Timeout partial; cache friends |
| Bad GPS | Jump across cells | Accuracy threshold; ignore outliers |
| Regional outage | Empty or stale | Fail partial; no fabricated precision |
If you remember one thing: Degraded = stale or empty nearby list; outage = fabricated precision or ignoring opt-in—never do the latter.
API design
| Endpoint | Role |
|---|---|
POST /v1/location:update | Opt-in required; body: quantized cell or raw (server quantizes) |
GET /v1/nearby/friends | Returns list with approx_distance_bucket, last_seen |
POST /v1/privacy:freeze | Stops updates |
Query params (GET /v1/nearby/friends):
| Param | Role |
|---|---|
radius_m | Max search radius (capped server-side) |
limit | Max results |
include_stale | Whether to show expired locations |
Diagram:
GET /nearby/friends?radius_m=500
--> Auth
--> Graph: friend_ids (cache)
--> Location index: cells from viewer pos
--> intersect + filter + rank --> JSON
Errors: 403 if not opt-in; 429 if abuse; empty 200 if no friends in range—not 404.
If you remember one thing: GET /nearby/friends returns coarse buckets + last_seen—never exact home addresses by default.
Production angles
Location plus social graphs combine spatial skew, privacy law, and human drama. Production is not “geohash plus Redis”—it is hot cells during events, stalking patterns that look like API traffic, and index writes that outrun mobile battery budgets.
Concerts, stadiums, and festivals — one cell becomes a city
What users saw — p99 latency for GET /nearby/friends spikes when everyone maps to the same H3/S2 cell. CPU on the spatial index shard redlines. Results truncate or time out even though global QPS looks normal.
Why — Posting lists per cell grow with crowd density. Intersection with friends stays large if the user has many friends onsite. No early termination or candidate cap in the retrieval plan.
What good teams do — Adaptive subcell splitting under load. Hard caps with deterministic ranking explained to users. Optional “event mode” pre-index when product allows. Precompute close-friends subgraph to shrink intersection cost.
Stalking reports and abuse
What users saw — User reports “someone knew where I was.” Legal asks who could see location. Internal actor queries a celebrity every minute from a support tool.
Why — Fine-grained location plus frequent updates equals a tracking surface. Predictable commute patterns re-identify people even with coarse display. No audit trail on queries—only on writes.
What good teams do — Audit who queried whom when policy requires. Coarser display or fuzzing for non-mutual friends. Rate limits and anomaly detection on repeated queries against one target. TTL and minimum sampling intervals. Privacy review before shipping map features.
Location write storms
What users saw — Mobile clients over-sample GPS after a bad release. Index writers fall behind. Reads return stale positions or empty sets inconsistently.
Why — Battery vs freshness tradeoff pushed to the server without admission control. Fan-out writes to multiple indices (cell + user document).
What good teams do — Throttle POST /location per device with 429 and Retry-After. Batch updates client-side. Backpressure when index lag exceeds SLO. Measure cells with highest cardinality, query p99, index lag.
[ Location write storm ] → index write QPS ↑
→ throttle clients → 429 on POST /location
How to use this in an interview — Tie spatial hot spots to candidate limits and privacy to audit and coarsening—not just geohash length. Close with why O(friends) refinement works when degree is bounded, but spatial search must never degenerate to O(all users).
Bottlenecks and tradeoffs
Precision vs privacy
The tension — Finer cells improve accuracy but worsen re-identification risk.
What breaks — Sub-meter dots enable stalking; regulators ask about retention.
What teams do — Coarse buckets in UI; shorter TTL; opt-in gates.
Say in the interview — Name display precision and retention together—not as afterthoughts.
Pull vs push notifications
The tension — Push “friend nearby” is engaging but spammy.
What breaks — Battery drain; notification fatigue at festivals.
What teams do — Quiet hours, dedupe, threshold distance before ping.
Say in the interview — Default to pull query; push is optional product with strict caps.
If you remember one thing: Hot cells and abuse surfaces are as important as the index choice.
What should stick
You do not need to memorize every index type. After this guide, you should be able to:
- Spatial prune before graph — Cells → candidates → ∩ friends → refine—never O(all users).
- Privacy by design — Opt-in, quantize, TTL, coarse display, freeze mode.
- Write throttling — Update on cell change or interval—not every GPS tick.
- Hot cells — Stadiums need caps, subcells, or event modes—not one giant posting list.
- Abuse is real — Rate limits, blocks, audit on queries where policy requires.
Tell it in the room: “Client quantizes GPS to a cell and sends updates sparingly. Server stores short-TTL location in a spatial index. Nearby query: cover radius with cells, fetch candidates, intersect with friend list and blocks, Haversine refine survivors, return coarse distance buckets with last_seen. Opt-in and freeze are enforced on every path.”
Reference diagram
What interviewers expect
Geohash grid updates; query friend's cells; throttle updates; privacy snapping.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Update frequency?
- Geospatial index?
- Privacy?
- Scale friends list?
- Battery?
Deep-dive questions and strong answer outlines
Location update?
Client sends every N sec or geofence exit; server stores geohash cell + timestamp in Redis.
Nearby query?
Fetch friend ids from graph; query friends in same/adjacent geohash cells; filter by distance exact.
Privacy?
Snap to grid; hide when user paused; coarse location for acquaintances tier.
Stale?
TTL hide if update > 15 min; show last seen policy.
Scale?
Shard by user region; partition location store by geohash.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: Always on GPS?
A: User controls precision and pause sharing.
Q: vs Google Maps?
A: Friend-filtered subset not global POI search.
Q: Background iOS?
A: Geofence significant-change API—brief.
Q: Harassment?
A: Block removes from graph queries immediately.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.