System design interview guide
Dropbox System Design
A user uploads a 10 GB video on hotel Wi-Fi—the upload must resume after disconnect while another device still shows "syncing" with the wrong version until metadata catches up. Chunked storage, revision sync, and conflict copies define Dropbox-class design.
Problem statement
Dropbox: chunked blob storage, metadata revisions, multi-device sync.
Introduction
You edit a slide deck on the train—offline. Your colleague saves a new version from the office at the same moment. Both laptops sync. One file wins. The other becomes report (conflicted copy).pptx. Neither of you planned for that—but the product must not lose bytes.
That is what users feel. The interview asks whether you can separate what changed in the folder tree from where the bytes live.
Dropbox-class systems are two-layer: a metadata plane (trees, versions, ACLs, journal) and a blob plane (content-addressed, cheap, replicated object storage). Interviewers watch whether you chunk and dedupe before you talk about databases, and whether you separate “what changed” from “where the bytes live.”
Weak answers stop at “S3 for files, Postgres for metadata.” Strong answers walk sync (cursor, conflicts), sharing (ACL on every read), and GC (chunk refcount after delete).
If you remember one thing: Metadata journal + content-addressed chunks—two planes, one sync story.
How to approach
Walk one file from laptop to cloud to phone—not “we use object storage.”
Clarify real-time co-editing vs file sync—scope changes the answer. Sketch namespace per user or team, change journal with monotonic seq, chunk upload with content hash, then conflict policy. Search is async—mention after core sync.
In the room: “I’ll confirm sync vs live co-edit scope, then walk chunk upload and journal commit before sharing and search.”
If you remember one thing: Scope first, then journal + chunks + conflict policy.
Interview tips
Five exchanges that test sync depth—not storage name-dropping.
Content addressing and dedup
You: “We store files in S3 by path.”
They ask: “Two users upload the same 2 GB installer—do you pay twice?”
Land here: Split files into chunks named by hash. Server skips upload if chunk exists. Refcount chunks for garbage collection after delete.
Timestamps vs journal
You: “We sync by comparing modified times.”
They ask: “Two offline edits, clocks skewed—who wins?”
Land here: Server journal sequence (seq) is authoritative for “what changed.” Use parent_rev on commit for optimistic concurrency—not mtime alone.
Sharing and ACLs
You: “Shared folder means everyone can read.”
They ask: “User revokes share—how fast does access actually stop?”
Land here: Effective permission = ACL + inheritance. Cache per-user permission views with TTL; revoke must invalidate quickly on the read path.
Large file bandwidth
You: “Re-upload the whole file on every change.”
They ask: “User tweaks one slide in a 500 MB deck?”
Land here: Chunk-level sync—only missing hashes upload. Mention delta/rsync-style block diff if pressed; at minimum chunk list diff.
Huge folder listing
You: “GET /folder returns all children.”
They ask: “Folder with a million files?”
Land here: Pagination, cursor, lazy expansion—never one response with every child.
If you remember one thing: Name hash, seq, parent_rev, ACL check, cursor—not “we’ll CDN it.”
Capacity estimation
| Topic | Angle |
|---|---|
| Metadata | Many small rows; shard by user_id / team_id / namespace_id |
| Blobs | EB-scale; egress cost dominates; CDN for shared links |
| Sync ops | Often exceed raw uploads—notification path must be cheap |
| Dedup ratio | Enterprise saves storage—refcount correctness must hold |
Implications: Metadata QPS drives sharding; hot folders need rate limits and efficient fan-out of change notifications.
If you remember one thing: Metadata QPS and egress dollars matter more than raw blob storage capacity.
High-level architecture
Desktop/mobile clients keep a local mirror + journal cursor. Metadata service (strongly consistent per shard) owns paths, file versions, chunk lists, sharing edges. Blob storage (S3-class) stores immutable chunks by hash. Notification service tells clients “something changed” so they pull delta from metadata API. Search indexer consumes async events—off hot path.
Who owns what:
- Metadata API — Authoritative tree; transactional
commitof new version; lists changes sincecursor. - Chunk gateway — Pre-signed uploads; verifies hash on complete; dedup skip if chunk exists.
- Object store — Durability; lifecycle to cold tier; encryption at rest.
- ACL service — Resolves share → effective access; cached with careful invalidation.
[ Client A ] ──sync──► [ Metadata svc ] ──► [ Metadata DB / shard ]
| |
| 1) list changes +-- journal (seq, ops)
| 2) get chunk hashes
v
[ Pre-signed GET/PUT ] ──► [ Object store (chunks by hash) ]
▲
|
[ Client B ] ◄──notify── [ Notification svc ] (WebSocket / FCM)
In the room: Say async clearly: commit returns fast; search index and thumbnails trail; sync correctness does not wait on thumbnail.
If you remember one thing: Notify → client pulls delta from metadata; blobs flow separately by hash.
Core design approaches
Metadata model
File: (namespace_id, path) → file_id → version → ordered chunk hashes + size + content hash of whole file (optional).
Folder: Tree node with children listing or materialized path table—trade join cost vs rename cost.
Sync strategies
Polling: Simple; wasteful at scale—use cursor or long poll.
Push notification: “Something changed in namespace” → client pulls delta—scales better than pushing full trees.
Conflict
LWW with server timestamp + conflict file foo (conflicted copy).txt—honest UX.
CRDT for text—only if real-time co-editing in scope—heavy.
If you remember one thing: Push “something changed” + client pull journal beats pushing full trees.
Detailed design
Write path (upload new version)
- Client splits file into chunks, computes SHA-256 per chunk.
- Client requests upload for missing hashes (server returns skip for dedup).
- PUT chunks to object store with pre-signed URLs.
- Client calls
commit:{path, parent_rev, chunk_list, client_rev}—server transactionally creates new version if parent matches; else conflict response.
Read path (another device sync)
- Client maintains
last_seqfor namespace. GET /changes?since=seqreturns ops: add/update/delete/move.- For each updated file, fetch chunk list if not cached locally; download missing chunks.
Sharing
POST /share creates edge (resource, grantee, role); read path checks grantee + inheritance; public link is separate token with scoped permission.
In the room: Walk upload: chunk → hash → prepare → PUT missing → commit with parent_rev. Other device: notify → GET /changes?since=seq → fetch missing chunks.
If you remember one thing: Write = chunks then commit; read = journal cursor then parallel chunk GET.
Key challenges
- Conflict detection: Optimistic concurrency with
rev; merge is product problem—technical answer is detect + surface. - Dedup GC: Delete file decrements refcounts; sweep unreferenced chunks async—race with concurrent uploads—transaction or epoch GC.
- Rename/move at scale: Single metadata txn per namespace shard; hot dirs need care.
- Share link abuse: Rate limit; virus scan async; DLP enterprise—brief mention.
If you remember one thing: Conflicts detect with parent_rev; dedup GC needs refcount discipline under concurrent uploads.
Scaling the system
- Shard metadata by namespace (user/team); avoid cross-shard moves or two-phase commit—design paths to stay in-shard when possible.
- Horizontal stateless metadata API with connection pooling to shards.
- Object store scales itself; hot chunks may need CDN for shared links.
- Rate limit sync list for noisy clients; bulkhead tenants.
If you remember one thing: Shard metadata by namespace; object store scales itself; hot folders need pagination and rate limits.
Failure handling
| Failure | Effect | Mitigation |
|---|---|---|
| Partial chunk upload | Orphan multipart | Lifecycle rule deletes incomplete after TTL |
| Commit fails after upload | Orphan chunks | GC + idempotent commit retry |
| Client offline | Divergent edits | Conflict rules; server wins on authoritative fields |
| Metadata replica lag | Stale read of ACL | Read-your-writes via primary for security checks |
Degraded UX: Stale file list briefly; outage is cannot access files—metadata HA matters more than blob (blobs are already replicated).
If you remember one thing: Partial uploads get lifecycle TTL; commit conflicts return 409—client merges or saves conflict copy.
API design
Chunk upload
| Method | Role |
|---|---|
POST /v1/chunks:prepare | Returns URLs + upload session id |
PUT to object store | Raw bytes |
POST /v1/chunks:complete | {hash, size} finalize |
File commit
POST /v1/files:commit
{
"path": "/docs/report.pdf",
"parent_rev": "abc",
"chunks": ["sha256:...", "..."],
"client_rev": "uuid"
}
Change feed
| Param | Role |
|---|---|
cursor | Last journal seq |
limit | Max ops |
Diagram:
Client --GET /changes?cursor=...--> Metadata
|
+-- ops: file X v3, new chunk hashes [h1,h2]
|
Client --GET missing chunks--> Object store (parallel)
Errors: 409 conflict on parent_rev; retry with merge UX; 412 if quota exceeded.
If you remember one thing: Hottest path is changes feed + parallel chunk fetch—design APIs around cursor pagination.
Production angles
Sync is a distributed state machine stretched across flaky networks, clocks that disagree, and clients you do not fully control. Operations lives in why the same hash appears twice, why one laptop never catches up, and why storage bills grow while users think they deleted everything.
Sync loops, battery drain, and “my Mac won’t sleep”
What users saw — Support sees “sync stuck” tickets spike. Fans spin; mobile telemetry shows wake locks held for hours. Metadata QPS from a small cohort of devices dwarfs healthy clients. Dashboards look green—damage is per-device churn.
Why — Something keeps producing no-op or conflicting journal entries: client bug re-applies the same patch, clock skew breaks ordering, or partial write leaves the client convinced the server is “behind.” Without server-side dedupe and per-device circuit breakers, one bad build self-DDoS metadata while returning 200s.
What good teams do — Hash verification on commit is non-negotiable. Rate-limit and backoff noisy device IDs. Alert on ops per device per minute and journal tail lag per namespace—not only global QPS. Kill switches per client version.
Storage cost climbs while users “deleted” files
What users saw — Object storage grew 30% quarter-over-quarter though MAU is flat. Legal asks why PII still exists for deleted accounts. Refcounts for deduped chunks never reach zero; GC jobs blocked behind compliance holds.
Why — Content-addressed storage means chunks live until every reference edge disappears. Cross-user dedup, shared links, version history, and litigation holds each pin bytes. GC is eventually correct; billing is monthly and impatient.
What good teams do — Metrics on GC backlog, bytes pending delete, oldest legal hold age. Tiered retention by tenant SKU. Explicit product switch to disable cross-user dedup where privacy requires it.
Share links slow far from “the” region
What users saw — Latency to first byte fine in us-east-1, awful in APAC. CDN cache hit ratio low—every share is a unique signed URL with short TTL. Correct for security; brutal for edge warmth.
Why — Control plane (signing, ACL) optimized; data plane egress on one spine. Signed GET patterns defeat naive cache keys unless you architect URL canonicalization and key separation deliberately.
What good teams do — Geo-replicated object storage or regional origins behind the same signer. Range requests and transfer acceleration for huge files. Separate SLOs for metadata vs bulk download.
Polling storms masquerading as success
What users saw — /changes p99 creeps during a client release. 429 rates tick up on older versions. Nothing is “down,” but commit latency for interactive saves rises because metadata serves empty polls.
Why — Mobile clients wake on push hints but still poll as backstop. A bug doubles poll frequency. Server keeps answering 200 with “no updates”—healthy on availability dashboards, bad for capacity.
What good teams do — Adaptive polling with jitter. 429 + Retry-After for abusive fingerprints. Conditional sync tokens so “nothing changed” is cheap. Measure journal lag, commit p99, dedup hit rate, GC backlog together.
[ Many clients poll /changes ] → metadata QPS ↑
→ throttle noisy clients → 429 + Retry-After
How to use this in an interview — Pick one pain: sync loop, undeleted bytes, or regional egress. Name one metric that goes red first and one containment lever (circuit break, GC visibility, or CDN/signer split).
Bottlenecks and tradeoffs
Consistency vs availability across shards
The tension — Strong per-namespace serializability is expensive cross-shard.
What breaks — Cross-shard moves need two-phase commit or careful path design.
What teams do — Scope moves to stay in-shard when possible; accept eventual cross-shard consistency for rare ops.
Say in the interview — Namespace sharding is a product constraint, not an afterthought.
Dedup vs privacy
The tension — Cross-user dedup saves storage but reveals shared chunks exist.
What breaks — Enterprise customers disable dedup; GC graphs get harder.
What teams do — Per-tenant dedup pools; product flag for “no cross-user dedup.”
Say in the interview — Name the privacy cost of global content addressing.
If you remember one thing: Metadata is the hot path; blobs are immutable; sync loops and GC backlog are ops reality.
What should stick
You do not need to memorize every service. After this guide, you should be able to:
- Two planes — Metadata journal vs content-addressed chunks in object storage.
- Chunk + hash + dedup — Upload missing hashes only; refcount for GC.
- Journal beats mtime —
seqcursor andparent_revfor conflicts—not clock compare alone. - Notify then pull — Push says “something changed”; client pulls delta cheaply.
- 409 is a feature — Conflict detection is technical; merge UX is product.
Tell it in the room: “Client chunks file, uploads missing hashes, commits version with parent_rev. Other devices get notify, pull changes since cursor, fetch missing chunks in parallel. Sharing checks effective ACL every read. Deletes decrement refcounts; GC sweeps unreferenced chunks async.”
Reference diagram
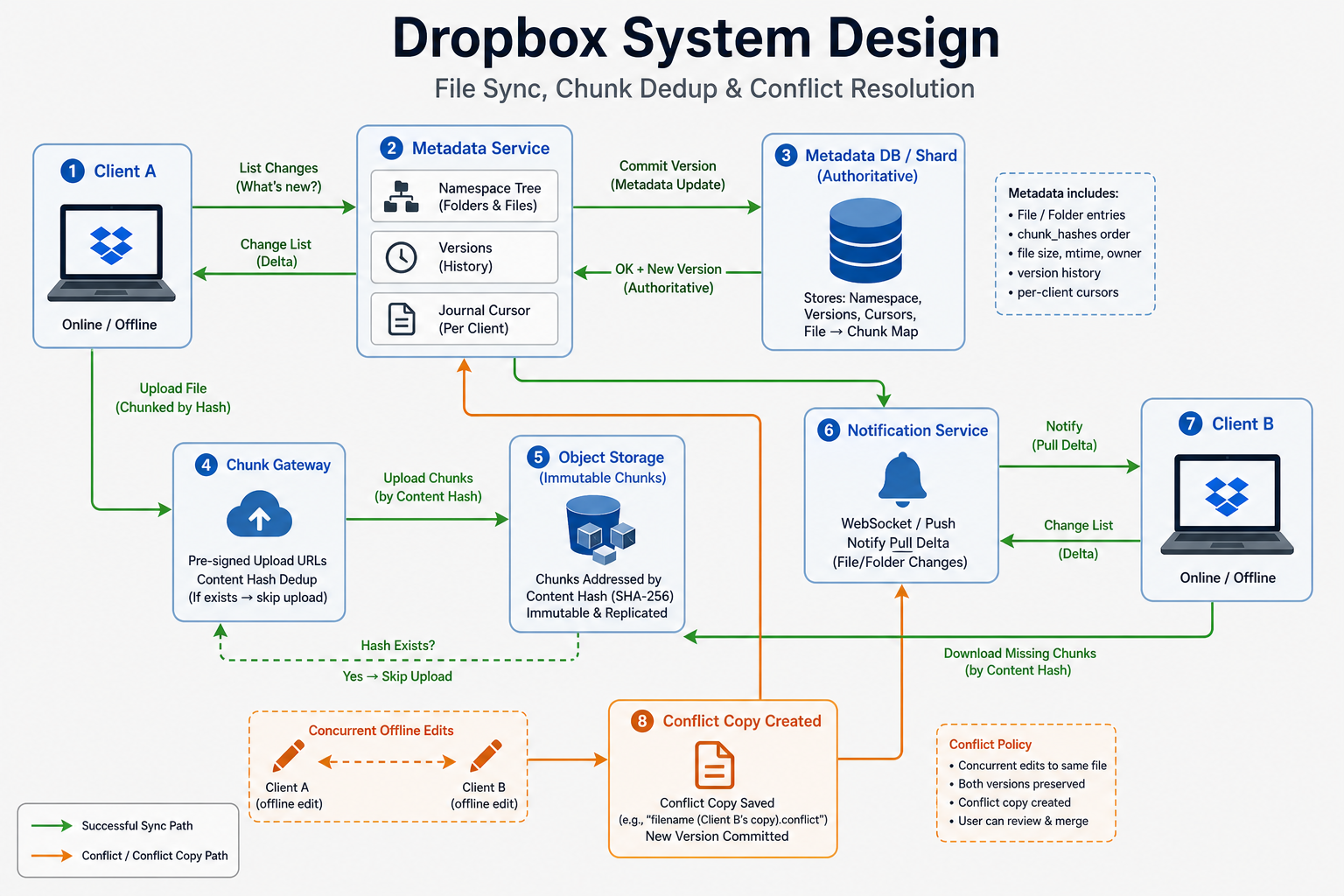
What interviewers expect
Content-defined chunks in blob store; metadata DB; delta sync by revision.
Interview workflow (template)
- Clarify requirements. Confirm functional scope, users, consistency needs, and which non-functional goals matter most (latency, availability, cost).
- Rough capacity. Estimate QPS, storage, and bandwidth so your data model and partitioning story are grounded.
- APIs and core flows. Define a minimal API and walk 1–2 critical read/write paths end to end.
- Data model and storage. Choose stores for each access pattern; call out hot keys, indexes, and retention.
- Scale and failure. Add caching, sharding, replication, queues, or fan-out as needed; say what breaks in failure modes.
- Tradeoffs. Name alternatives you rejected and why (e.g. strong vs eventual consistency, sync vs async).
Frequently asked follow-ups
- Large file upload?
- Sync algorithm?
- Conflicts?
- Dedup?
- Share link security?
Deep-dive questions and strong answer outlines
Upload resume?
Chunk hash list; upload missing chunks; commit manifest atomically on complete.
Sync?
Long poll or websocket notify; client compares revision; fetch changed file metadata list only.
Conflict?
Server detects base revision mismatch; create conflict copy; user merges manually.
Dedup?
Content-hash chunks shared storage with ref count; encryption breaks cross-user dedup.
Share?
Tokenized link maps to file_id + ACL; short TTL optional; audit downloads.
AI feedback on your design
After a practice session, InterviewCrafted summarizes strengths, gaps, and interviewer-style expectations—similar to a written debrief. See a static example report, then practice this problem to get feedback on your own answer.
FAQs
Q: vs Google Drive real-time?
A: Dropbox batch sync vs OT—different conflict model.
Q: E2E?
A: Client keys; server stores ciphertext chunks only.
Q: Team folders?
A: Namespace ACL inheritance.
Q: Delete sync?
A: Tombstone revision propagates.
Practice interactively
Open the practice session to use the canvas and stages, then review AI feedback.